

К этому времени вы уже изучили большинство повседневных команд и способы организации рабочего процесса, необходимые для того, чтобы поддерживать Git-репозиторий для контроля вашего исходного кода. Вы выполнили основные задания, связанные с добавлением файлов под версионный контроль и записью сделанных изменений, и вы вооружились мощью подготовительной области (staging area), легковесного ветвления и слияния.
Сейчас вы познакомитесь с множеством весьма сильных возможностей Git’а. Вы совсем не обязательно будете использовать их каждый день, но, возможно, в какой-то момент они вам понадобятся.
Git позволяет указывать конкретные коммиты или их последовательности несколькими способами. Они не всегда очевидны, но иногда их полезно знать.
Вы можете просто сослаться на коммит по его SHA-1 хешу, но также существуют более понятные для человека способы ссылаться на коммиты. В этом разделе кратко описаны различные способы обратиться к одному определённому коммиту.
Git достаточно умён для того, чтобы понять какой коммит вы имеете в виду по первым нескольким символам (частичному хешу), конечно, если их не меньше четырёх и они однозначны, то есть если хеш только одного объекта в вашем репозитории начинается с этих символов.
Предположим, что вы хотите посмотреть содержимое какого-то конкретного коммита. Вы выполняете команду git log и находите этот коммит (например, тот, в котором вы добавили какую-то функциональность):
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
В нашем случае выберем коммит 1c002dd..... При использовании git show для просмотра содержимого этого коммита следующие команды эквивалентны (предполагая, что сокращённые версии однозначны):
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git может показать короткие уникальные сокращения ваших SHA-1 хешей. Если вы передадите опцию --abbrev-commit команде git log, то её вывод будет использовать сокращённые значения, сохраняя их уникальными; по умолчанию будут использоваться семь символов, но при необходимости длина будет увеличена для сохранения однозначности хешей:
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
В общем случае восемь-десять символов более чем достаточно для уникальности внутри проекта. В одном из самых больших проектов, использующих Git, ядре Linux только начинает появляться необходимость использовать 12 символов из 40 возможных для сохранения уникальности.
Многие люди интересуются, что произойдёт, если они в какой-то момент, по некоторой случайности, получат два объекта в репозитории, которые будут иметь два одинаковых значения SHA-1 хеша. Что тогда?
Если вы вдруг закоммитите объект, SHA-1 хеш которого такой же, как у некоторого предыдущего объекта в вашем репозитории, Git обнаружит предыдущий объект в своей базе данных и посчитает, что он уже был записан. Если вы в какой-то момент попытаетесь получить этот объект опять, вы всегда будете получать данные первого объекта.
Однако, вы должны осознавать то, как смехотворно маловероятен этот сценарий. Длина SHA-1 составляет 20 байт или 160 бит. Количество случайно хешированных объектов, необходимое для того, чтобы получить 50% вероятность одиночного совпадения составляет порядка 2^80 (формула для определения вероятности совпадения: p = (n(n-1)/2) * (1/2^160))). 2^80 это 1.2 x 10^24 или один миллион миллиарда миллиардов. Это в 1200 раз больше количества песчинок на земле.
Вот пример для того, чтобы вы поняли, что необходимо, чтобы получить SHA-1 коллизию. Если бы все 6.5 миллиардов людей на Земле программировали и каждую секунду каждый из них производил количество кода, эквивалентное всей истории ядра Linux (1 миллион Git-объектов) и отправлял его в один огромный Git-репозиторий, то потребовалось бы 5 лет для того, чтобы заполнить репозиторий достаточно для того, чтобы получить 50% вероятность единичной SHA-1 коллизии. Более вероятно, что каждый член вашей команды программистов будет атакован и убит волками в несвязанных друг с другом случаях в одну и ту же ночь.
Для самого прямого метода указать коммит необходимо, чтобы этот коммит имел ветку, ссылающуюся на него. Тогда вы можете использовать имя ветки в любой команде Git’а, которая ожидает коммит или значение SHA-1. Например, если вы хотите посмотреть последний коммит в ветке, следующие команды эквивалентны, предполагая, что ветка topic1 ссылается на ca82a6d:
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show topic1
Чтобы посмотреть, на какой именно SHA указывает ветка, или понять для какого-то из приведённых примеров, к каким SHA он сводится, можно использовать служебную (plumbing) утилиту Git’а, которая называется rev-parse. Более подробно о служебных утилитах будет говориться в лекции 5; в основном rev-parse нужна для выполнения низкоуровневых операций и не предназначена для использования в повседневной работе. Однако, она может пригодиться, если вам необходимо разобраться, что происходит на самом деле. Сейчас вы можете попробовать применить rev-parse к своей ветке.
$ git rev-parse topic1
ca82a6dff817ec66f44342007202690a93763949
Одна из вещей, которую Git делает в фоновом режиме, пока вы работаете, это запоминание ссылочного лога — лога того, где находились HEAD и ветки в течение последних нескольких месяцев.
Ссылочный лог можно просмотреть с помощью git reflog:
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
Каждый раз, когда верхушка ветки обновляется по какой-либо причине, Git сохраняет информацию об этом в эту временную историю. И вы можете использовать и эти данные для задания старых коммитов. Если вы хотите посмотреть, какое значение было у HEAD в вашем репозитории пять шагов назад, используйте ссылку вида @{n} так же, как показано в выводе команды reflog:
$ git show HEAD@{5}
Также вы можете использовать эту команду, чтобы увидеть, где ветка была некоторое время назад. Например, чтобы увидеть, где была ветка master вчера, наберите
$ git show master@{yesterday}
Эта команда покажет, где верхушка ветки находилась вчера. Такой подход работает только для данных, которые всё ещё находятся в ссылочном логе. Так что вы не сможете использовать его для коммитов с давностью в несколько месяцев.
Чтобы просмотреть информацию ссылочного лога в таком же формате, как вывод git log, можно выполнить git log -g:
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Важно отметить, что информация в ссылочном логе строго локальная — это лог того, чем вы занимались со своим репозиторием. Ссылки не будут теми же самыми в чьей-то чужой копии репозитория; и после того как вы только что склонировали репозиторий, ссылочный лог будет пустым, так как вы ещё ничего не делали со своим репозиторием. Команда git show HEAD@{2.months.ago} сработает, только если вы склонировали свой проект как минимум два месяца назад. Если вы склонировали его пять минут назад, то вы ничего не получите.
Ещё один основной способ указать коммит — указать коммит через его предков. Если поставить ^ в конце ссылки, для Git’а это будет означать родителя этого коммита. Допустим, история вашего проекта выглядит следующим образом:
$ git log --pretty=format:'%h %s' --graph
* 734713b fixed refs handling, added gc auto, updated tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b Some rdoc changes
* | 1c002dd added some blame and merge stuff
|/
* 1c36188 ignore *.gem
* 9b29157 add open3_detach to gemspec file list
В этом случае вы можете посмотреть предыдущий коммит, указав HEAD^, что означает “родитель HEAD”:
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Вы также можете указать некоторое число после ^. Например, d921970^2 означает “второй родитель коммита d921970”. Такой синтаксис полезен только для коммитов-слияний, которые имеют больше, чем одного родителя. Первый родитель — это ветка, на которой вы находились во время слияния, а второй — коммит на ветке, которая была слита:
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
Другое основное обозначение для указания на предков — это ~. Это тоже ссылка на первого родителя, поэтому HEAD~ и HEAD^ эквивалентны. Различия становятся очевидными, только когда вы указываете число. HEAD~2 означает первого родителя первого родителя HEAD или прародителя — это переход по первым родителям указанное количество раз. Например, для показанной выше истории, HEAD~3 будет
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
То же самое можно записать как HEAD^^^, что опять же означает первого родителя первого родителя первого родителя:
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Кроме того, можно комбинировать эти обозначения. Например, можно получить второго родителя для предыдущей ссылки (мы предполагаем, что это коммит-слияние) написав HEAD~3^2, ну и так далее.
Теперь, когда вы умеете задавать отдельные коммиты, разберёмся, как указать диапазон коммитов. Это особенно полезно при управлении ветками — если у вас много веток, вы можете использовать обозначения диапазонов, чтобы ответить на вопросы типа “Какие в этой ветке есть коммиты, которые не были слиты в основную ветку?”
Наиболее распространённый способ задать диапазон коммитов — это запись с двумя точками. По существу, таким образом вы просите Git взять набор коммитов, достижимых из одного коммита, но не достижимых из другого. Например, пускай ваша история коммитов выглядит так, как показано на рисунке 6-1.
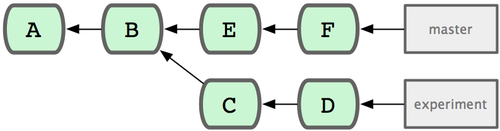
Рисунок 3-1. Пример истории для выбора набора коммитов.
Допустим, вы хотите посмотреть, что в вашей ветке experiment ещё не было слито в ветку master. Можно попросить Git показать вам лог только таких коммитов с помощью master..experiment — эта запись означает “все коммиты, достижимые из experiment, которые недостижимы из master”. Для краткости и большей понятности в примерах мы будем использовать буквы для обозначения коммитов на диаграмме вместо настоящего вывода лога в том порядке, в каком они будут отображены:
$ git log master..experiment
D
C
С другой стороны, если вы хотите получить обратное — все коммиты в master, которых нет в experiment, можно переставить имена веток. Запись experiment..master покажет всё, что есть в master, но недостижимо из experiment:
$ git log experiment..master
F
E
Такое полезно, если вы хотите, чтобы ветка experiment была обновлённой, и хотите посмотреть, что вы собираетесь в неё слить. Ещё один частый случай использования этого синтаксиса — посмотреть, что вы собираетесь отправить на удалённый сервер:
$ git log origin/master..HEAD
Эта команда покажет вам все коммиты в текущей ветке, которых нет в ветке master на сервере origin. Если бы вы выполнили git push, при условии, что текущая ветка отслеживает origin/master, то коммиты, которые перечислены в выводе git log origin/master..HEAD это те коммиты, которые были бы отправлены на сервер. Кроме того, можно опустить одну из сторон в такой записи — Git подставит туда HEAD. Например, вы можете получить такой же результат, как и в предыдущем примере, набрав git log origin/master.. — Git подставит HEAD сам, если одна из сторон отсутствует.
Запись с двумя точками полезна как сокращение, но, возможно, вы захотите указать больше двух веток, чтобы указать нужную ревизию. Например, чтобы посмотреть, какие коммиты находятся в одной из нескольких веток, но не в текущей. Git позволяет сделать это с помощью использования либо символа ^, либо --not перед любыми ссылками, коммиты, достижимые из которых, вы не хотите видеть. Таким образом, следующие три команды эквивалентны:
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
Это удобно, потому что с помощью такого синтаксиса можно указать более двух ссылок в своём запросе, чего вы не сможете сделать с помощью двух точек. Например, если вы хотите увидеть все коммиты достижимые из refA или refB, но не из refC, можно набрать одну из таких команд:
$ git log refA refB ^refC
$ git log refA refB --not refC
Всё это делает систему выбора ревизий очень мощной, что должно помочь вам определять, что содержится в ваших ветках.
Последняя основная запись для выбора диапазона коммитов — это запись с тремя точками, которая означает те коммиты, которые достижимы по одной из двух ссылок, но не по обеим одновременно. Вернёмся к примеру истории коммитов на рисунке 3-1. Если вы хотите увидеть, что находится в master или experiment, но не в обоих сразу, выполните
$ git log master...experiment
F
E
D
C
Повторимся, что это даст вам стандартный log-вывод, но покажет только информацию об этих четырёх коммитах, упорядоченных по дате коммита, как и обычно.
В этом случае вместе с командой log обычно используют параметр --left-right, который показывает, на какой стороне диапазона находится каждый коммит. Это помогает сделать данные полезнее:
$ git log --left-right master...experiment
< F
< E
> D
> C
С помощью этих инструментов вы можете намного легче объяснить Git’у, какой коммит или коммиты вы хотите изучить.
Вместе с Git’ом поставляется пара сценариев (script), облегчающих выполнение некоторых задач в командной строке. Сейчас мы посмотрим на несколько интерактивных команд, которые помогут вам легко смастерить свои коммиты так, чтобы включить в них только определённые части файлов. Эти инструменты сильно помогают в случае, когда вы поменяли кучу файлов, а потом решили, что хотите, чтобы эти изменения были в нескольких сфокусированных коммитах, а не в одном большом путанном коммите. Так вы сможете убедиться, что ваши коммиты — это логически разделённые наборы изменений, которые будет легко просматривать другим разработчикам, работающим с вами. Если вы выполните git add с опцией -i или --interactive, Git перейдёт в режим интерактивной оболочки и покажет что-то похожее на это:
$ git add -i
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now>
Как видите, эта команда показывает содержимое индекса, но в другом виде — по сути, ту же информацию вы получили бы при вызове git status, но здесь она в более сжатом и информативном виде. git add -i показывает проиндексированные изменения слева, а непроиндексированные — справа.
Затем идёт раздел Commands (команды). Тут можно сделать многие вещи, включая добавление файлов в индекс, удаление файлов из индекса, индексирование файлов частями, добавление неотслеживаемых файлов и просмотр дельт (diff) проиндексированных изменений.
Если набрать 2 или u в приглашении What now>, сценарий спросит, какие файлы вы хотите добавить в индекс:
What now> 2
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
Чтобы проиндексировать файлы TODO и index.html, нужно набрать их номера:
Update>> 1,2
staged unstaged path
* 1: unchanged +0/-1 TODO
* 2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
Символ * рядом с каждым файлом означает, что файл выбран для индексирования. Если вы сейчас ничего не будете вводить, а нажмёте Enter в приглашении Update>>, то Git возьмёт всё, что уже выбрано, и добавит в индекс:
Update>>
updated 2 paths
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Как видите, теперь файлы TODO и index.html проиндексированы (staged), а файл simplegit.rb — всё ещё нет. Если в этот момент вы хотите удалить файл TODO из индекса, используйте опцию 3 или r (revert):
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 3
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> 1
staged unstaged path
* 1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> [enter]
reverted one path
Взглянув на статус снова, вы увидите, что файл TODO удалён из индекса:
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Чтобы посмотреть дельту для проиндексированных изменений, используйте команду 6 или d (diff). Она покажет вам список проиндексированных файлов, и вы сможете выбрать те, для которых хотите посмотреть дельту. Это почти то же, что указать git diff --cached в командной строке:
*** Commands ***
1: status 2: update 3: revert 4: add untracked
5: patch 6: diff 7: quit 8: help
What now> 6
staged unstaged path
1: +1/-1 nothing index.html
Review diff>> 1
diff --git a/index.html b/index.html
index 4d07108..4335f49 100644
--- a/index.html
+++ b/index.html
@@ -16,7 +16,7 @@ Date Finder
<p id="out">...</p>
-<div id="footer">contact : support@github.com</div>
+<div id="footer">contact : email.support@github.com</div>
<script type="text/javascript">
С помощью этих базовых команд вы можете использовать интерактивный режим для git add, чтобы немного проще работать со своим индексом.
Для Git’а также возможно индексировать определённые части файлов, а не всё сразу. Например, если вы сделали несколько изменений в файле simplegit.rb и хотите проиндексировать одно из них, а другое — нет, то сделать такое в Git’е очень легко. В строке приглашения интерактивного режима наберите 5 или p (patch). Git спросит, какие файлы вы хотите индексировать частями; затем для каждой части изменений в выбранных файлах один за другим будут показываться куски дельт файла, и вас будут спрашивать, хотите ли вы занести их в индекс:
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index dd5ecc4..57399e0 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -22,7 +22,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log -n 25 #{treeish}")
+ command("git log -n 30 #{treeish}")
end
def blame(path)
Stage this hunk [y,n,a,d,/,j,J,g,e,?]?
На этой стадии у вас много вариантов действий. Набрав ?, вы получите список возможных действий:
Stage this hunk [y,n,a,d,/,j,J,g,e,?]? ?
y - stage this hunk (добавить этот кусок в индекс)
n - do not stage this hunk (не добавлять этот кусок в индекс)
a - stage this and all the remaining hunks in the file (добавить этот и все оставшиеся куски в этом файле в индекс)
d - do not stage this hunk nor any of the remaining hunks in the file (не добавлять в индекс ни этот, ни последующие куски в этом файле)
g - select a hunk to go to (выбрать кусок и перейти к нему)
/ - search for a hunk matching the given regex (поиск куска по регулярному выражению)
j - leave this hunk undecided, see next undecided hunk (отложить решение для этого куска, перейти к следующему отложенному куску)
J - leave this hunk undecided, see next hunk (отложить решение для этого куска, перейти к следующему куску)
k - leave this hunk undecided, see previous undecided hunk (отложить решение для этого куска, перейти к предыдущему отложенному куску)
K - leave this hunk undecided, see previous hunk (отложить решение для этого куска, перейти к предыдущему куску)
s - split the current hunk into smaller hunks (разбить текущий кусок на меньшие части)
e - manually edit the current hunk (отредактировать текущий кусок вручную)
? - print help (вывести справку)
Как правило, вы будете использовать y или n для индексирования каждого куска, но индексирование всех кусков сразу в некоторых файлах или откладывание решения на потом также может оказаться полезным. Если вы добавите в индекс одну часть файла, а другую часть — нет, вывод статуса будет выглядеть так:
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: +1/-1 +4/-0 lib/simplegit.rb
Статус файла simplegit.rb выглядит любопытно. Он показывает, что часть строк в индексе, а часть — не в индексе. Мы частично проиндексировали этот файл. Теперь вы можете выйти из интерактивного сценария и выполнить git commit, чтобы создать коммит из этих частично проиндексированных файлов.
В заключение скажем, что нет необходимости входить в интерактивный режим git add, чтобы выполнять индексирование частями — вы можете запустить тот же сценарий, набрав git add -p или git add --patch в командной строке.
Часто возникает такая ситуация, что пока вы работаете над частью своего проекта, всё находится в беспорядочном состоянии, а вам нужно переключить ветки, чтобы немного поработать над чем-то другим. Проблема в том, что вы не хотите делать коммит с наполовину доделанной работой только для того, чтобы позже можно было вернуться в это же состояние. Ответ на эту проблему — команда git stash.
Прятанье поглощает грязное состояние рабочего каталога, то есть изменённые отслеживаемые файлы и изменения в индексе, и сохраняет их в стек незавершённых изменений, которые вы потом в любое время можете снова применить.
Чтобы продемонстрировать, как это работает, предположим, что вы идёте к своему проекту и начинаете работать над парой файлов и, возможно, добавляете в индекс одно из изменений. Если вы выполните git status, вы увидите грязное состояние проекта:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#
Теперь вы хотите поменять ветку, но не хотите делать коммит с тем, над чем вы ещё работаете; тогда вы прячете эти изменения. Чтобы создать новую “заначку”, выполните git stash:
$ git stash
Saved working directory and index state \
"WIP on master: 049d078 added the index file"
HEAD is now at 049d078 added the index file
(To restore them type "git stash apply")
Ваш рабочий каталог чист:
$ git status
# On branch master
nothing to commit (working directory clean)
В данный момент вы легко можете переключить ветки и поработать где-то ещё; ваши изменения сохранены в стеке. Чтобы посмотреть, что у вас есть припрятанного, используйте git stash list:
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to log
В нашем случае две “заначки” были сделаны ранее, так что у вас теперь три разных припрятанных работы. Вы можете снова применить ту, которую только что спрятали, с помощью команды, показанной в справке в выводе первоначальной команды stash: git stash apply. Если вы хотите применить одну из старых заначек, можете сделать это, указав её имя так: git stash apply stash@{2}. Если не указывать ничего, Git будет подразумевать, что вы хотите применить последнюю спрятанную работу:
$ git stash apply
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: index.html
# modified: lib/simplegit.rb
#
Как видите, Git восстановил изменения в файлах, которые вы отменили, когда использовали команду stash. В нашем случае у вас был чистый рабочий каталог, когда вы восстанавливали спрятанные изменения, и к тому же вы делали это на той же ветке, на которой находились во время прятанья. Но наличие чистого рабочего каталога и применение на той же ветке не обязательны для git stash apply. Вы можете спрятать изменения на одной ветке, переключиться позже на другую ветку и попытаться восстановить изменения. У вас в рабочем каталоге также могут быть изменённые и недокоммиченные файлы во время применения спрятанного — Git выдаст вам конфликты слияния, если что-то уже не может быть применено чисто.
Изменения в файлах были восстановлены, но файлы в индексе — нет. Чтобы добиться такого, необходимо выполнить команду git stash apply с опцией --index, тогда команда попытается применить изменения в индексе. Если бы вы выполнили команду так, а не как раньше, то получили бы исходное состояние:
$ git stash apply --index
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#
Всё, что делает опция apply — это пытается применить спрятанную работу — то, что вы спрятали, всё ещё будет находиться в стеке. Чтобы удалить спрятанное, выполните git stash drop с именем “заначки”, которую нужно удалить:
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051... Revert "added file_size"
stash@{2}: WIP on master: 21d80a5... added number to log
$ git stash drop stash@{0}
Dropped stash@{0} (364e91f3f268f0900bc3ee613f9f733e82aaed43)
Также можно выполнить git stash pop, чтобы применить спрятанные изменения и сразу же удалить их из стека.
При некоторых сценариях использования, может понадобиться применить спрятанные изменения, поработать, а потом отменить изменения, внесённые командой stash apply. Git не предоставляет команды stash unapply, но можно добиться того же эффекта получив сначала патч для спрятанных изменений, а потом применив его в перевёрнутом виде:
$ git stash show -p stash@{0} | git apply -R
Снова, если вы не указываете параметр для stash, Git подразумевает то, что было спрятано последним:
$ git stash show -p | git apply -R
Если хотите, сделайте псевдоним и добавьте в свой Git команду stash-unapply. Например, так:
$ git config --global alias.stash-unapply '!git stash show -p | git apply -R'
$ git stash
$ #... work work work
$ git stash-unapply
Если вы спрятали какие-то наработки и оставили их на время, а в это время продолжили работать на той же ветке, то у вас могут возникнуть трудности с восстановлением спрятанной работы. Если apply попытается изменить файл, который вы редактировали после прятанья, то возникнет конфликт слияния, который надо будет разрешить. Если нужен более простой способ снова потестировать спрятанную работу, можно выполнить команду git stash branch, которая создаст вам новую ветку с началом из того коммита, на котором вы находились во время прятанья, восстановит в ней вашу работу и затем удалит спрятанное, если оно применилось успешно:
$ git stash branch testchanges
Switched to a new branch "testchanges"
# On branch testchanges
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: lib/simplegit.rb
#
Dropped refs/stash@{0} (f0dfc4d5dc332d1cee34a634182e168c4efc3359)
Это сокращение удобно для того, чтобы легко восстановить свою работу, а затем поработать над ней в новой ветке.
Неоднократно во время работы с Git’ом, вам может захотеться по какой-либо причине исправить свою историю коммитов. Одна из чудесных особенностей Git’а заключается в том, что он даёт возможность принять решение в самый последний момент. Используя индекс, вы можете решить, какие файлы пойдут в какие коммиты, непосредственно перед тем, как сделать коммит. Вы можете воспользоваться командой stash, решив, что над чем-то ещё не стоило начинать работать. А также вы можете переписать уже сделанные коммиты так, будто они были сделаны как-то по-другому. В частности, это может быть изменение порядка следования коммитов, редактирование сообщений или модифицирование файлов в коммите, уплотнение и разделение коммитов, а также полное удаление некоторых коммитов — но только до того, как вы поделитесь наработками с другими.
В этом разделе вы узнаете, как делать подобные полезные вещи, чтобы перед публикацией приводить историю коммитов в желаемый вид.
Изменение последнего коммита — это, вероятно, наиболее типичный случай переписывания истории, который вы будете делать. Как правило, вам от вашего последнего коммита понадобятся две основные вещи: изменить сообщение коммита или изменить только что записанный снимок состояния, добавив, изменив или удалив из него файлы.
Если вы всего лишь хотите изменить сообщение последнего коммита — это очень просто:
$ git commit --amend
Выполнив это, вы попадёте в свой текстовый редактор, в котором будет находиться сообщение последнего коммита, готовое к тому, чтобы его отредактировали. Когда вы сохраните текст и закроете редактор, Git создаст новый коммит с вашим сообщением и сделает его новым последним коммитом.
Если вы сделали коммит и затем хотите изменить снимок состояния в коммите, добавив или изменив файлы, допустим, потому что вы забыли добавить только что созданный файл, когда делали коммит, то процесс выглядит в основном так же. Вы добавляете в индекс изменения, которые хотите, редактируя файл и выполняя для него git add или выполняя git rm для отслеживаемого файла, и затем git commit --amend возьмёт текущий индекс и сделает его снимком состояния нового коммита.
Будьте осторожны, используя этот приём, потому что git commit --amend меняет SHA-1 коммита. Тут как с маленьким перемещением (rebase) — не правьте последний коммит, если вы его уже куда-то отправили.
Чтобы изменить коммит, находящийся глубоко в истории, вам придётся перейти к использованию более сложных инструментов. В Git’е нет специального инструмента для редактирования истории, но вы можете использовать rebase для перемещения ряда коммитов на то же самое место, где они были изначально, а не куда-то в другое место. Используя инструмент для интерактивного перемещения, вы можете останавливаться на каждом коммите, который хотите изменить, и редактировать сообщение, добавлять файлы или делать что-то ещё. Интерактивное перемещение можно запустить, добавив опцию -i к git rebase. Необходимо указать, насколько далёкие в истории коммиты вы хотите переписать, сообщив команде, на какой коммит выполняется перемещение.
Например, если вы хотите изменить сообщения последних трёх коммитов или сообщения для только некоторых коммитов в этой группе, вам надо передать в git rebase -i в качестве аргумента родителя последнего коммита, который вы хотите изменить, то есть HEAD~2^ или HEAD~3. Наверное, проще запомнить ~3, потому что вы пытаетесь отредактировать три последних коммита, но имейте в виду, что на самом деле вы обозначили четвёртый сверху коммит — родительский коммит для того, который хотите отредактировать:
$ git rebase -i HEAD~3
Снова напомним, что это команда для перемещения, то есть все коммиты в диапазоне HEAD~3..HEAD будут переписаны вне зависимости от того, меняли ли вы в них сообщение или нет. Не трогайте те коммиты, которые вы уже отправили на центральный сервер — сделав так, вы запутаете других разработчиков, дав им разные версии одних и тех же изменений.
Запуск этой команды выдаст вам в текстовом редакторе список коммитов, который будет выглядеть следующим образом:
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
# Rebase 710f0f8..a5f4a0d onto 710f0f8
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#
Важно отметить, что эти коммиты выведены в обратном порядке по сравнению с тем, как вы их обычно видите, используя команду log. Запустив log, вы получите что-то вроде этого:
$ git log --pretty=format:"%h %s" HEAD~3..HEAD
a5f4a0d added cat-file
310154e updated README formatting and added blame
f7f3f6d changed my name a bit
Обратите внимание на обратный порядок. Интерактивное перемещение выдаёт сценарий, который будет выполнен. Он начнётся с коммита, который вы указали в командной строке (HEAD~3), и воспроизведёт изменения, сделанные каждым из этих коммитов, сверху вниз. Наверху указан самый старый коммит, а не самый новый, потому что он будет воспроизведён первым.
Вам надо отредактировать сценарий так, чтобы он останавливался на коммитах, которые вы хотите отредактировать. Чтобы сделать это, замените слово pick на слово edit для каждого коммита, на котором сценарий должен остановиться. Например, чтобы изменить сообщение только для третьего коммита, отредактируйте файл так, чтобы он выглядел следующим образом:
edit f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
Когда вы сохраните и выйдете из редактора, Git откатит вас назад к последнему коммиту в списке и выкинет вас в командную строку, выдав следующее сообщение:
$ git rebase -i HEAD~3
Stopped at 7482e0d... updated the gemspec to hopefully work better
You can amend the commit now, with
git commit --amend
Once you’re satisfied with your changes, run
git rebase --continue
В этой инструкции в точности сказано, что надо сделать. Наберите
$ git commit --amend
Измените сообщение коммита и выйдите из редактора. Теперь выполните
$ git rebase --continue
Данная команда применит оставшиеся два коммита автоматически и закончит на этом. Если вы измените pick на edit для большего количества строк, то вы повторите эти шаги для каждого коммита, где вы напишете edit. Каждый раз Git будет останавливаться, давая вам исправить коммит, а потом, когда вы закончите, будет продолжать.
Интерактивное перемещение можно также использовать для изменения порядка следования и для полного удаления коммитов. Если вы хотите удалить коммит “added cat-file” и поменять порядок, в котором идут два других коммита, измените сценарий для rebase с такого
pick f7f3f6d changed my name a bit
pick 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
на такой:
pick 310154e updated README formatting and added blame
pick f7f3f6d changed my name a bit
Когда вы сохраните и выйдете из редактора, Git откатит вашу ветку к родительскому для этих трёх коммиту, применит 310154e, затем f7f3f6d, а потом остановится. Вы фактически поменяли порядок следования коммитов и полностью удалили коммит “added cat-file”.
С помощью интерактивного перемещения также возможно взять несколько коммитов и сплющить их в один коммит. Сценарий выдаёт полезное сообщение с инструкциями для перемещения:
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#
Если вместо “pick” или “edit” указать “squash”, Git применит изменения и из этого коммита, и из предыдущего, а затем даст вам объединить сообщения для коммитов. Итак, чтобы сделать один коммит из трёх наших коммитов, надо сделать так, чтобы сценарий выглядел следующим образом:
pick f7f3f6d changed my name a bit
squash 310154e updated README formatting and added blame
squash a5f4a0d added cat-file
Когда вы сохраните и выйдете из редактора, Git применит все три изменения, а затем опять выдаст вам редактор для того, чтобы объединить сообщения трёх коммитов:
# This is a combination of 3 commits.
# The first commit's message is:
changed my name a bit
# This is the 2nd commit message:
updated README formatting and added blame
# This is the 3rd commit message:
added cat-file
Когда вы это сохраните, у вас будет один коммит, который вносит изменения такие же, как три бывших коммита.
Разбиение коммита — это отмена коммита, а затем индексирование изменений частями и добавление коммитов столько раз, сколько коммитов вы хотите получить. Предположим, что вы хотите разбить средний из наших трёх коммитов. Вместо “updated README formatting and added blame” вы хотите получить два отдельных коммита: “updated README formatting” в качестве первого и “added blame” в качестве второго. Вы можете сделать это в сценарии rebase -i, поставив “edit” в инструкции для коммита, который хотите разбить:
pick f7f3f6d changed my name a bit
edit 310154e updated README formatting and added blame
pick a5f4a0d added cat-file
Когда вы сохраните и выйдете из редактора, Git откатится к родителю первого коммита в списке, применит первый коммит (f7f3f6d), применит второй (310154e) и выбросит вас в консоль. Здесь вы можете сбросить последний коммит в смешанном режиме с помощью git reset HEAD^ — это в сущности отменит этот коммит и оставит изменённые файлы непроиндексированными. Теперь вы можете взять сброшенные изменения и создать из них несколько коммитов. Просто добавляйте файлы в индекс и делайте коммиты, пока не сделаете несколько штук. Затем, когда закончите, выполните git rebase --continue:
$ git reset HEAD^
$ git add README
$ git commit -m 'updated README formatting'
$ git add lib/simplegit.rb
$ git commit -m 'added blame'
$ git rebase --continue
Когда Git применит последний коммит (a5f4a0d) в сценарии, история будет выглядеть так:
$ git log -4 --pretty=format:"%h %s"
1c002dd added cat-file
9b29157 added blame
35cfb2b updated README formatting
f3cc40e changed my name a bit
Повторимся ещё раз, что эта операция меняет SHA всех коммитов в списке, так что убедитесь, что ни один из коммитов в этом списке вы ещё не успели отправить в общий репозиторий.
Есть ещё один вариант переписывания истории, который можно использовать, если надо переписать большое количество коммитов в автоматизируемой форме — например, везде поменять свой e-mail адрес или удалить файл из каждого коммита — это команда filter-branch. Она может переписать огромные периоды вашей истории, так что, возможно, вообще не стоит использовать её, если ваш проект успел стать публичным и другие люди уже работают на основе коммитов, которые вы собрались переписать. Однако, она может быть весьма полезной. Мы посмотрим на некоторые типичные варианты использования команды так, чтобы вы получили представление о тех вещах, на которые она способна.
Такое случается довольно часто. Кто-нибудь случайно добавляет в коммит огромный бинарный файл, необдуманно выполнив git add ., и вы хотите удалить его отовсюду. Или, может быть, вы нечаянно добавили в коммит файл содержащий пароль, а теперь хотите сделать код этого проекта открытым. filter-branch — это тот инструмент, который вы наверняка захотите использовать, чтобы прочесать всю историю. Чтобы удалить файл с именем passwords.txt изо всей истории, используйте опцию --tree-filter для filter-branch:
$ git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
Rewrite 6b9b3cf04e7c5686a9cb838c3f36a8cb6a0fc2bd (21/21)
Ref 'refs/heads/master' was rewritten
Опция --tree-filter выполняет указанную команду после выгрузки каждой версии проекта и затем заново делает коммит из результата. В нашем случае мы удалили файл с именем passwords.txt из каждого снимка состояния независимо от того, существовал ли он там или нет. Если вы хотите удалить все случайно добавленные резервные копии, сделанные вашим текстовым редактором, выполните что-то типа git filter-branch --tree-filter "find * -type f -name '*~' -delete" HEAD.
Вы увидите, как Git переписывает деревья и коммиты, а в конце переставляет указатель ветки. Как правило, хороший вариант — делать это в тестовой ветке, а затем жёстко сбрасывать ветку master с помощью reset --hard, когда вы поймёте, что результат — это то, чего вы действительно добивались. Чтобы запустить filter-branch для всех веток, можно передать команде параметр --all.
Предположим, вы импортировали репозиторий из другой системы контроля версий, и в нём есть бессмысленные каталоги (trunk, tags, и др.). Если вы хотите сделать trunk новым корнем проекта, команда filter-branch может помочь вам сделать и это:
$ git filter-branch --subdirectory-filter trunk HEAD
Rewrite 856f0bf61e41a27326cdae8f09fe708d679f596f (12/12)
Ref 'refs/heads/master' was rewritten
Теперь всюду корневой каталог проекта будет в подкаталоге trunk. Git также автоматически удалит все коммиты, которые не затрагивают данный подкаталог.
Ещё один типичный случай — это, когда вы забыли выполнить git config, чтобы задать своё имя и e-mail адрес, перед тем как начать работать. Или, возможно, вы хотите открыть код своего проекта с работы и поменять все свои рабочие e-mail’ы на свой личный адрес. В любом случае с помощью filter-branch вы с таким же успехом можете поменять адреса почты в нескольких коммитах за один раз. Вам надо быть аккуратным, чтобы не поменять и чужие адреса, поэтому используйте --commit-filter:
$ git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEAD
Эта команда проходит по всем коммитам и переписывает их так, чтобы там был указан новый адрес. Так как коммиты содержат значения SHA-1 своих родителей, эта команда поменяет все SHA в вашей истории, а не только те, в которых есть указанный e-mail адрес.
Git также предоставляет несколько инструментов, призванных помочь вам в отладке ваших проектов. Так как Git сконструирован так, чтобы работать с практически любыми типами проектов, эти инструменты довольно общие, но зачастую они могут помочь отловить ошибку или её виновника, если что-то пошло не так.
Если вы отловили ошибку в коде и хотите узнать, когда и по какой причине она была внесена, то аннотация файла — лучший инструмент для этого случая. Он покажет вам, какие коммиты модифицировали каждую строку файла в последний раз. Так что, если вы видите, что какой-то метод в коде содержит ошибку, то можно сделать аннотацию нужного файла с помощью git blame, чтобы посмотреть, когда и кем каждая строка метода была в последний раз отредактирована. В этом примере используется опция -L, чтобы ограничить вывод строками с 12ой по 22ую:
$ git blame -L 12,22 simplegit.rb
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 12) def show(tree = 'master')
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 13) command("git show #{tree}")
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 14) end
^4832fe2 (Scott Chacon 2008-03-15 10:31:28 -0700 15)
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 16) def log(tree = 'master')
79eaf55d (Scott Chacon 2008-04-06 10:15:08 -0700 17) command("git log #{tree}")
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 18) end
9f6560e4 (Scott Chacon 2008-03-17 21:52:20 -0700 19)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 20) def blame(path)
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 21) command("git blame #{path}")
42cf2861 (Magnus Chacon 2008-04-13 10:45:01 -0700 22) end
Заметьте, что первое поле — это частичная SHA-1 коммита, в котором последний раз менялась строка. Следующие два поля — это значения, полученные из этого коммита — имя автора и дата создания коммита. Так что вы легко можете понять, кто и когда менял данную строку. Затем идут номера строк и содержимое файла. Также обратите внимание на строки с ^4832fe2, это те строки, которые находятся здесь со времён первого коммита для этого файла. Это коммит, в котором этот файл был впервые добавлен в проект, и с тех пор те строки не менялись. Это всё несколько сбивает с толку, потому что только что вы увидели по крайней мере три разных способа изменить SHA коммита с помощью ^, но тут вот такое значение.
Ещё одна крутая вещь в Git’е — это то, что он не отслеживает переименования файлов в явном виде. Он записывает снимки состояний, а затем пытается выяснить, что было переименовано неявно уже после того, как это случилось. Одна из интересных функций, возможная благодаря этому, заключается в том, что вы можете попросить дополнительно выявить все виды перемещений кода. Если вы передадите -C в git blame, Git проанализирует аннотируемый файл и попытается выявить, откуда фрагменты кода в нём появились изначально, если они были скопированы откуда-то. Недавно я занимался разбиением файла GITServerHandler.m на несколько файлов, один из которых был GITPackUpload.m. Вызвав blame с опцией -C для GITPackUpload.m, я могу понять откуда части кода здесь появились:
$ git blame -C -L 141,153 GITPackUpload.m
f344f58d GITServerHandler.m (Scott 2009-01-04 141)
f344f58d GITServerHandler.m (Scott 2009-01-04 142) - (void) gatherObjectShasFromC
f344f58d GITServerHandler.m (Scott 2009-01-04 143) {
70befddd GITServerHandler.m (Scott 2009-03-22 144) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 145)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 146) NSString *parentSha;
ad11ac80 GITPackUpload.m (Scott 2009-03-24 147) GITCommit *commit = [g
ad11ac80 GITPackUpload.m (Scott 2009-03-24 148)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 149) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 150)
56ef2caf GITServerHandler.m (Scott 2009-01-05 151) if(commit) {
56ef2caf GITServerHandler.m (Scott 2009-01-05 152) [refDict setOb
56ef2caf GITServerHandler.m (Scott 2009-01-05 153)
Это действительно удобно. Стандартно вам бы выдали в качестве начального коммита тот коммит, в котором вы скопировали код, так как это первый коммит, в котором вы поменяли эти строки в данном файле. А сейчас Git выдал вам изначальный коммит, в котором эти строки были написаны, несмотря на то, что это было в другом файле.
Аннотирование файла помогает, когда вы знаете, где у вас ошибка, и есть с чего начинать. Если вы не знаете, что у вас сломалось, и с тех пор, когда код работал, были сделаны десятки или сотни коммитов, вы наверняка обратитесь за помощью к git bisect. Команда bisect выполняет бинарный поиск по истории коммитов, и призвана помочь как можно быстрее определить, в каком коммите была внесена ошибка.
Положим, вы только что отправили новую версию вашего кода в производство, и теперь вы периодически получаете отчёты о какой-то ошибке, которая не проявлялась, пока вы работали над кодом, и вы не представляете, почему код ведёт себя так. Вы возвращаетесь к своему коду, и у вас получается воспроизвести ошибку, но вы не понимаете, что не так. Вы можете использовать bisect, чтобы выяснить это. Сначала выполните git bisect start, чтобы запустить процесс, а затем git bisect bad, чтобы сказать системе, что текущий коммит, на котором вы сейчас находитесь, сломан. Затем, необходимо сказать bisect, когда было последнее известное хорошее состояние с помощью git bisect good [хороший_коммит]:
$ git bisect start
$ git bisect bad
$ git bisect good v1.0
Bisecting: 6 revisions left to test after this
[ecb6e1bc347ccecc5f9350d878ce677feb13d3b2] error handling on repo
Git выяснил, что между коммитом, который вы указали как последний хороший коммит (v1.0), и текущей плохой версией было сделано примерно 12 коммитов, и он выгрузил вам версию из середины. В этот момент вы можете провести свои тесты и посмотреть, проявляется ли проблема в этом коммите. Если да, то она была внесена где-то раньше этого среднего коммита; если нет, то проблема появилась где-то после коммита в середине. Положим, что оказывается, что проблема здесь не проявилась, и вы сообщаете об этом Git’у, набрав git bisect good, и продолжаете свой путь:
$ git bisect good
Bisecting: 3 revisions left to test after this
[b047b02ea83310a70fd603dc8cd7a6cd13d15c04] secure this thing
Теперь вы на другом коммите, посередине между тем, который только что был протестирован и вашим плохим коммитом. Вы снова проводите тесты и выясняете, что текущий коммит сломан. Так что вы говорите об этом Git’у с помощью git bisect bad:
$ git bisect bad
Bisecting: 1 revisions left to test after this
[f71ce38690acf49c1f3c9bea38e09d82a5ce6014] drop exceptions table
Этот коммит хороший, и теперь у Git’а есть вся необходимая информация, чтобы определить, где проблема была внесена впервые. Он выдаёт вам SHA-1 первого плохого коммита и некоторую информацию о нём, а также какие файлы были изменены в этом коммите, так что вы сможете понять, что случилось, что могло внести эту ошибку:
$ git bisect good
b047b02ea83310a70fd603dc8cd7a6cd13d15c04 is first bad commit
commit b047b02ea83310a70fd603dc8cd7a6cd13d15c04
Author: PJ Hyett <pjhyett@example.com>
Date: Tue Jan 27 14:48:32 2009 -0800
secure this thing
:040000 040000 40ee3e7821b895e52c1695092db9bdc4c61d1730
f24d3c6ebcfc639b1a3814550e62d60b8e68a8e4 M config
Если вы закончили, необходимо выполнить git bisect reset, чтобы сбросить HEAD туда, где он был до начала бинарного поиска, иначе вы окажетесь в странном состоянии:
$ git bisect reset
Это мощный инструмент, который поможет вам за считанные минуты проверить сотни коммитов в поисках появившейся ошибки. На самом деле, если у вас есть сценарий (script), который возвращает на выходе 0, если проект хороший и не 0, если проект плохой, то вы можете полностью автоматизировать git bisect. Для начала ему снова надо задать область бинарного поиска, задав известные хороший и плохой коммиты. Если хотите, можете сделать это, указав команде bisect start известный плохой коммит первым, а хороший вторым:
$ git bisect start HEAD v1.0
$ git bisect run test-error.sh
Сделав так, вы получите, что test-error.sh будет автоматически запускаться на каждом выгруженном коммите, пока Git не найдёт первый сломанный коммит. Вы также можете запускать что-нибудь типа make или make tests или что-то там ещё, что запускает ваши автоматические тесты.
Зачастую случается так, что во время работы над некоторым проектом появляется необходимость использовать внутри него ещё какой-то проект. Возможно, библиотеку, разрабатываемую сторонними разработчиками или разрабатываемую вами обособленно и используемую в нескольких родительских проектах. Типичная проблема, возникающая при использовании подобного сценария, это, как сделать так, чтобы иметь возможность рассматривать эти два проекта как отдельные, всё же имея возможность использовать один проект внутри другого.
Вот пример. Предположим, вы разрабатываете веб-сайт и создаёте Atom-ленты. И вместо того, чтобы писать собственный код, генерирующий Atom, вы решили использовать библиотеку. Вы, вероятно, должны либо подключить нужный код с помощью разделяемой библиотеки, такой как устанавливаемый модуль CPAN или пакет RubyGem, либо скопировать исходный код в дерево собственного проекта. Проблема с подключением библиотеки в том, что библиотеку сложно хоть как-то модифицировать под свои нужды, и зачастую её сложнее распространять. Ведь вы вынуждены удостовериться в том, что эта библиотека доступна на каждом клиенте. Проблема с включением кода в ваш собственный проект в том, что любые изменения, вносимые вами, могут конфликтовать с изменениями, которые появятся в основном проекте, и эти изменения будет сложно слить.
Git решает эту задачу, используя подмодули (submodule). Подмодули позволяют содержать один Git-репозиторий как подкаталог другого Git-репозитория. Это даёт возможность клонировать ещё один репозиторий внутрь проекта, храня коммиты для этого репозитория отдельно.
Предположим, вы хотите добавить библиотеку Rack (интерфейс шлюза веб-сервера Ruby) в свой проект, возможно, внося свои собственные изменения в него, но продолжая сливать их с изменениями основного проекта. Первое, что вам требуется сделать, это клонировать внешний репозиторий в подкаталог. Добавление внешних проектов в качестве подмодулей делается командой git submodule add:
$ git submodule add git://github.com/chneukirchen/rack.git rack
Initialized empty Git repository in /opt/subtest/rack/.git/
remote: Counting objects: 3181, done.
remote: Compressing objects: 100% (1534/1534), done.
remote: Total 3181 (delta 1951), reused 2623 (delta 1603)
Receiving objects: 100% (3181/3181), 675.42 KiB | 422 KiB/s, done.
Resolving deltas: 100% (1951/1951), done.
Теперь у вас внутри проекта в подкаталоге с именем rack находится проект Rack. Вы можете переходить в этот подкаталог, вносить изменения, добавить ваш собственный доступный для записи внешний репозиторий для отправки в него своих изменений, извлекать и сливать из исходного репозитория и многое другое. Если вы выполните git status сразу после добавления подмодуля, то увидите две вещи:
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: .gitmodules
# new file: rack
#
Вначале вы заметите файл .gitmodules. Это конфигурационный файл, который содержит соответствие между URL проекта и локальным подкаталогом, в который был загружен подмодуль:
$ cat .gitmodules
[submodule "rack"]
path = rack
url = git://github.com/chneukirchen/rack.git
Если у вас несколько подмодулей, то в этом файле будет несколько записей. Важно обратить внимание на то, что этот файл находится под версионным контролем вместе с другими вашими файлами, так же как и файл .gitignore. Он отправляется при выполнении push и загружается при выполнении pull вместе с остальными файлами проекта. Так другие люди, которые клонируют этот проект, узнают, откуда взять проекты-подмодули.
В следующем листинге вывода git status присутствует элемент rack. Если вы выполните git diff для него, то увидите кое-что интересное:
$ git diff --cached rack
diff --git a/rack b/rack
new file mode 160000
index 0000000..08d709f
--- /dev/null
+++ b/rack
@@ -0,0 +1 @@
+Subproject commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433
Хотя rack является подкаталогом в вашем рабочем каталоге, Git видит его как подмодуль и не отслеживает его содержимое, если вы не находитесь в нём. Вместо этого, Git записывает его как один конкретный коммит из этого репозитория. Если вы производите изменения в этом подкаталоге и делаете коммит, основной проект замечает, что HEAD в подмодуле был изменён, и регистрирует тот хеш коммита, над которым вы в данный момент завершили работу в подмодуле. Таким образом, если кто-то склонирует этот проект, он сможет воссоздать окружение в точности.
Это важная особенность подмодулей – вы запоминаете их как определенный коммит (состояние), в котором они находятся. Вы не можете записать подмодуль под ссылкой master или какой-либо другой символьной ссылкой.
Если вы создадите коммит, то увидите что-то вроде этого:
$ git commit -m 'first commit with submodule rack'
[master 0550271] first commit with submodule rack
2 files changed, 4 insertions(+), 0 deletions(-)
create mode 100644 .gitmodules
create mode 160000 rack
Обратите внимание на режим 160000 для элемента rack. Это специальный режим в Git’е, который по существу означает, что в качестве записи в каталоге сохраняется коммит, а не подкаталог или файл.
Вы можете обращаться с каталогом rack как с отдельным проектом и время от времени обновлять свой “надпроект” с помощью указателя на самый последний коммит в этом подпроекте. Все команды Git’а в этих двух каталогах работают независимо друг от друга:
$ git log -1
commit 0550271328a0038865aad6331e620cd7238601bb
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Apr 9 09:03:56 2009 -0700
first commit with submodule rack
$ cd rack/
$ git log -1
commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433
Author: Christian Neukirchen <chneukirchen@gmail.com>
Date: Wed Mar 25 14:49:04 2009 +0100
Document version change
Сейчас мы склонируем проект, содержащий подмодуль. После получения такого проекта в вашей копии будут каталоги, содержащие подмодули, но пока что без единого файла в них:
$ git clone git://github.com/schacon/myproject.git
Initialized empty Git repository in /opt/myproject/.git/
remote: Counting objects: 6, done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 0 (delta 0)
Receiving objects: 100% (6/6), done.
$ cd myproject
$ ls -l
total 8
-rw-r--r-- 1 schacon admin 3 Apr 9 09:11 README
drwxr-xr-x 2 schacon admin 68 Apr 9 09:11 rack
$ ls rack/
$
Каталог rack присутствует, но он пустой. Необходимо выполнить две команды: git submodule init для инициализации вашего локального файла конфигурации и git submodule update для получения всех данных из подмодуля и перехода к соответствующему коммиту, указанному в вашем основном проекте:
$ git submodule init
Submodule 'rack' (git://github.com/chneukirchen/rack.git) registered for path 'rack'
$ git submodule update
Initialized empty Git repository in /opt/myproject/rack/.git/
remote: Counting objects: 3181, done.
remote: Compressing objects: 100% (1534/1534), done.
remote: Total 3181 (delta 1951), reused 2623 (delta 1603)
Receiving objects: 100% (3181/3181), 675.42 KiB | 173 KiB/s, done.
Resolving deltas: 100% (1951/1951), done.
Submodule path 'rack': checked out '08d709f78b8c5b0fbeb7821e37fa53e69afcf433'
Теперь ваш подкаталог rack точно в том состоянии, в котором он был, когда вы раньше делали коммит. Если другой разработчик внесёт изменения в код rack и затем сделает коммит, а вы потом обновите эту ссылку и сольёте её, то вы получите что-то странное:
$ git merge origin/master
Updating 0550271..85a3eee
Fast forward
rack | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
[master*]$ git status
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: rack
#
Вы слили то, что по существу является изменением указателя на подмодуль. Но при этом обновления кода в каталоге подмодуля не произошло, так что всё выглядит так, как будто вы имеете грязное состояние в своём рабочем каталоге:
$ git diff
diff --git a/rack b/rack
index 6c5e70b..08d709f 160000
--- a/rack
+++ b/rack
@@ -1 +1 @@
-Subproject commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
+Subproject commit 08d709f78b8c5b0fbeb7821e37fa53e69afcf433
Это всё из-за того, что ваш указатель на подмодуль не соответствует тому, что на самом деле находится в каталоге подмодуля. Чтобы исправить это, необходимо снова выполнить git submodule update:
$ git submodule update
remote: Counting objects: 5, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 1), reused 2 (delta 0)
Unpacking objects: 100% (3/3), done.
From git@github.com:schacon/rack
08d709f..6c5e70b master -> origin/master
Submodule path 'rack': checked out '6c5e70b984a60b3cecd395edd5b48a7575bf58e0'
Вы вынуждены делать так каждый раз, когда вы получаете изменения подмодуля в главном проекте. Это странно, но это работает.
Распространённая проблема возникает, когда разработчик делает изменения в своей локальной копии подмодуля, но не отправляет их на общий сервер. Затем он создаёт коммит содержащий указатель на это непубличное состояние и отправляет его в основной проект. Когда другие разработчики пытаются выполнить git submodule update, система работы с подмодулями не может найти указанный коммит, потому что он существует только в системе первого разработчика. Если такое случится, вы увидите ошибку вроде этой:
$ git submodule update
fatal: reference isn’t a tree: 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Unable to checkout '6c5e70b984a60b3cecd395edd5ba7575bf58e0' in submodule path 'rack'
Вам надо посмотреть, кто последним менял подмодуль:
$ git log -1 rack
commit 85a3eee996800fcfa91e2119372dd4172bf76678
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Apr 9 09:19:14 2009 -0700
added a submodule reference I will never make public. hahahahaha!
А затем отправить этому человеку письмо со своими возмущениями.
Иногда разработчики хотят объединить подкаталоги крупного проекта в нечто связанное в зависимости от того, в какой они команде. Это типично для людей, перешедших с CVS или Subversion, где они определяли модуль или набор подкаталогов, и они хотят сохранить данный тип рабочего процесса.
Хороший способ сделать такое в Git’е — это сделать каждый из подкаталогов отдельным Git-репозиторием, и создать Git-репозиторий для суперпроекта, который будет содержать несколько подмодулей. Преимущество такого подхода в том, что вы можете более гибко определять отношения между проектами при помощи меток и ветвей в суперпроектах.
Однако, использование подмодулей не обходится без загвоздок. Во-первых, вы должны быть относительно осторожны, работая в каталоге подмодуля. Когда вы выполняете команду git submodule update, она возвращает определённую версию проекта, но не внутри ветви. Это называется состоянием с отделённым HEAD (detached HEAD) — это означает, что файл HEAD указывает на конкретный коммит, а не на символическую ссылку. Проблема в том, что вы, скорее всего, не хотите работать в окружении с отделённым HEAD, потому что так легко потерять изменения. Если вы сделаете первоначальный submodule update, сделаете коммит в каталоге подмодуля, не создавая ветки для работы в ней, и затем вновь выполните git submodule update из основного проекта, без создания коммита в суперпроекте, Git затрёт ваши изменения без предупреждения. Технически вы не потеряете проделанную работу, но у вас не будет ветки, указывающей на неё, так что будет несколько сложновато её восстановить.
Для предотвращения этой проблемы создавайте ветвь, когда работаете в каталоге подмодуля с использованием команды git checkout -b work или какой-нибудь аналогичной. Когда вы сделаете обновление подмодуля командой submodule update в следующий раз, она всё же откатит вашу работу, но, по крайней мере, у вас будет указатель для возврата назад.
Переключение веток с подмодулями в них также может быть мудрёным. Если вы создадите новую ветку, добавите туда подмодуль и затем переключитесь обратно, туда где не было этого подмодуля, вы всё ещё будете иметь каталог подмодуля в виде неотслеживаемого каталога:
$ git checkout -b rack
Switched to a new branch "rack"
$ git submodule add git@github.com:schacon/rack.git rack
Initialized empty Git repository in /opt/myproj/rack/.git/
...
Receiving objects: 100% (3184/3184), 677.42 KiB | 34 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
$ git commit -am 'added rack submodule'
[rack cc49a69] added rack submodule
2 files changed, 4 insertions(+), 0 deletions(-)
create mode 100644 .gitmodules
create mode 160000 rack
$ git checkout master
Switched to branch "master"
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# rack/
Вы будете вынуждены либо переместить каталог подмодуля в другое место, либо удалить его. В случае удаления вам потребуется клонировать его снова при переключении обратно, и тогда вы можете потерять локальные изменения или ветки, которые не были отправлены в основной репозиторий.
Последняя проблема, которая возникает у многих, и о которой стоит предостеречь, возникает при переходе от подкаталогов к подмодулям. Если вы держали некоторые файлы под версионным контролем в своём проекте, а сейчас хотите перенести их в подмодуль, вам надо быть осторожным, иначе Git разозлится на вас. Допустим, вы держите файлы rack в подкаталоге проекта, и вы хотите вынести его в подмодуль. Если вы просто удалите подкаталог и затем выполните submodule add, Git наорёт на вас:
$ rm -Rf rack/
$ git submodule add git@github.com:schacon/rack.git rack
'rack' already exists in the index
Вначале вам следует убрать каталог rack из индекса (убрать из-под версионного контроля). Потом можете добавить подмодуль:
$ git rm -r rack
$ git submodule add git@github.com:schacon/rack.git rack
Initialized empty Git repository in /opt/testsub/rack/.git/
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 88 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
Теперь, предположим, вы сделали это в ветке. Если вы попытаетесь переключиться обратно на ту ветку, где эти файлы всё ещё в актуальном дереве, а не в подмодуле, то вы получите такую ошибку:
$ git checkout master
error: Untracked working tree file 'rack/AUTHORS' would be overwritten by merge.
Вам следует переместить каталог подмодуля rack, перед тем, как вы сможете переключиться на ветку, которая не содержит его:
$ mv rack /tmp/
$ git checkout master
Switched to branch "master"
$ ls
README rack
Затем, когда вы переключитесь обратно, вы получите пустой каталог rack. Вы сможете либо выполнить git submodule update для повторного клонирования, или вернуть содержимое вашего каталога /tmp/rack обратно в пустой каталог.
Теперь, когда вы увидели сложности системы подмодулей, давайте посмотрим на альтернативный путь решения той же проблемы. Когда Git выполняет слияние, он смотрит на то, что требуется слить воедино, и потом выбирает подходящую стратегию слияния. Если вы сливаете две ветви, Git использует рекурсивную (recursive) стратегию. Если вы объединяете более двух ветвей, Git выбирает стратегию осьминога (octopus). Эти стратегии выбираются за вас автоматически потому, что рекурсивная стратегия может обрабатывать сложные трёхсторонние ситуации слияния — например, более чем один общий предок — но она может сливать только две ветви. Слияние методом осьминога может справиться с множеством веток, но является более осторожным, чтобы предотвратить сложные конфликты, так что этот метод является стратегией по умолчанию при слиянии более двух веток.
Однако, существуют другие стратегии, которые вы также можете выбрать. Одна из них — слияние поддеревьев (subtree), и вы можете использовать его для решения задачи с подпроектами. Сейчас вы увидите, как выполнить то же встраивание rack, как и в предыдущем разделе, но с использованием стратегии слияния поддеревьев.
Идея слияния поддеревьев состоит в том, что у вас есть два проекта, и один из проектов отображается в подкаталог другого и наоборот. Если вы зададите в качестве стратегии слияния метод subtree, то Git будет достаточно умён, чтобы понять, что один из проектов является поддеревом другого и выполнит слияние в соответствии с этим. И это довольно удивительно.
Сначала добавим приложение Rack в проект. Добавим проект Rack как внешнюю ссылку в свой проект, и затем поместим его в отдельную ветку:
$ git remote add rack_remote git@github.com:schacon/rack.git
$ git fetch rack_remote
warning: no common commits
remote: Counting objects: 3184, done.
remote: Compressing objects: 100% (1465/1465), done.
remote: Total 3184 (delta 1952), reused 2770 (delta 1675)
Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done.
Resolving deltas: 100% (1952/1952), done.
From git@github.com:schacon/rack
* [new branch] build -> rack_remote/build
* [new branch] master -> rack_remote/master
* [new branch] rack-0.4 -> rack_remote/rack-0.4
* [new branch] rack-0.9 -> rack_remote/rack-0.9
$ git checkout -b rack_branch rack_remote/master
Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master.
Switched to a new branch "rack_branch"
Теперь у нас есть корень проекта Rack в ветке rack_branch и наш проект в ветке master. Если вы переключитесь на одну ветку, а затем на другую, то увидите, что содержимое их корневых каталогов различно:
$ ls
AUTHORS KNOWN-ISSUES Rakefile contrib lib
COPYING README bin example test
$ git checkout master
Switched to branch "master"
$ ls
README
Допустим, вы хотите поместить проект Rack в подкаталог своего проекта в ветке master. Вы можете сделать это в Git’е командой git read-tree. Вы узнаете больше про команду read-tree и её друзей в главе 9, а пока достаточно знать, что она считывает корень дерева одной ветки в индекс и рабочий каталог. Вам достаточно переключиться обратно на ветку master и вытянуть ветку rack в подкаталог rack основного проекта из ветки master:
$ git read-tree --prefix=rack/ -u rack_branch
После того как вы сделаете коммит, все файлы проекта Rack будут находиться в этом подкаталоге — будто вы скопировали их туда из архива. Интересно то, что вы можете довольно легко слить изменения из одной ветки в другую. Так что если проект Rack изменится, вы сможете вытянуть изменения из основного проекта, переключившись в его ветку и выполнив git pull:
$ git checkout rack_branch
$ git pull
Затем вы можете слить эти изменения обратно в свою главную ветку. Можно использовать git merge -s subtree — это сработает правильно, но тогда Git, кроме того, объединит вместе истории, чего вы, вероятно, не хотите. Чтобы получить изменения и заполнить сообщение коммита, используйте опции --squash и --no-commit вместе с опцией стратегии -s subtree:
$ git checkout master
$ git merge --squash -s subtree --no-commit rack_branch
Squash commit -- not updating HEAD
Automatic merge went well; stopped before committing as requested
Все изменения из проекта Rack слиты и готовы для локальной фиксации. Вы также можете сделать наоборот — внести изменения в подкаталог rack вашей ветки master, и затем слить их в ветку rack_branch, чтобы позже представить их мейнтейнерам или отправить их в основной репозиторий проекта с помощью git push.
Для получения разности между тем, что у вас есть в подкаталоге rack и кодом в вашей ветке rack_branch, чтобы увидеть нужно ли вам объединять их, вы не можете использовать нормальную команду diff. Вместо этого вы должны выполнить git diff-tree с веткой, с которой вы хотите сравнить:
$ git diff-tree -p rack_branch
Или, для сравнения того, что в вашем подкаталоге rack с тем, что было в ветке master на сервере во время последнего обновления, можно выполнить:
$ git diff-tree -p rack_remote/master
Вы познакомились с рядом продвинутых инструментов, которые позволяют вам манипулировать вашими коммитами и индексом более совершенно. Если вы заметите проблему, то без труда сможете определить, каким коммитом она внесена, когда и кем. Если вы хотите использовать подпроекты в своём проекте — вы узнали несколько путей, как приспособиться к этим нуждам. К этому моменту вы должны уметь делать в Git’е большинство тех вещей, которые вам понадобятся для повседневной работы в командной строке, и при этом вы будете чувствовать себя комфортно.
До этого момента мы описывали основы того, как Git работает, и как его использовать. Также мы познакомились с несколькими предоставляемыми Git’ом инструментами, которые делают его использование простым и эффективным. В этой главе мы пройдёмся по некоторым действиям, которые вы можете предпринять, чтобы заставить Git работать в нужной именно вам манере. Мы рассмотрим несколько важных настроек и систему перехватчиков (hook). С их помощью легко сделать так, чтобы Git работал именно так, как вам, вашей компании или вашей группе нужно.
В первой главе вкратце было рассказано, как можно изменить настройки Git’а с помощью команды git config. Одна из первых вещей, которую мы тогда сделали, это установили свои имя и e-mail адрес:
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.com
Теперь мы разберём пару более интересных опций, которые вы можете задать тем же образом, чтобы настроить Git под себя.
Мы уже рассмотрели некоторые детали настройки Git’а в первой главе, но давайте сейчас быстренько пройдёмся по ним снова. Git использует набор конфигурационных файлов для задания желаемого нестандартного поведения. Первым местом, в котором Git ищет заданные параметры, является файл /etc/gitconfig, содержащий значения, действующие для всех пользователей системы и всех их репозиториев. Когда вы передаёте git config опцию --system, происходит чтение или запись именно этого файла.
Следующее место, в которое Git заглядывает, это файл ~/.gitconfig, который для каждого пользователя свой. Вы можете заставить Git читать или писать этот файл, передав опцию --global.
И наконец, Git ищет заданные настройки в конфигурационном файле в Git-каталоге (.git/config) того репозитория, который вы используете в данный момент. Значения оттуда относятся к данному конкретному репозиторию. Значения настроек на новом уровне переписывают значения, заданные на предыдущем уровне. Поэтому, например, значения из .git/config перебивают значения в /etc/gitconfig. Позволяется задавать настройки путём редактирования конфигурационного файла вручную, используя правильный синтаксис, но, как правило, проще воспользоваться командой git config.
Настройки конфигурации, поддерживаемые Git’ом, можно разделить на две категории: клиентские и серверные. Большинство опций — клиентские, они задают предпочтения в вашей личной работе. Несмотря на то, что опций доступно великое множество, мы рассмотрим только некоторые из них — те, которые широко используются или значительно влияют на вашу работу. Многие опции полезны только в редких случаях, которые мы не будем здесь рассматривать. Если вы хотите посмотреть список всех опций, которые есть в вашем Git’е, выполните:
$ git config --help
В странице руководства для git config все доступные опции описаны довольно подробно.
Для создания и редактирования сообщений коммитов и меток Git по умолчанию использует тот редактор, который установлен текстовым редактором по умолчанию в вашей системе, или, как запасной вариант, редактор Vi. Чтобы сменить это умолчание на что-нибудь другое, используйте настройку core.editor:
$ git config --global core.editor emacs
Теперь неважно, что установлено в качестве вашего редактора по умолчанию в переменной оболочки, при редактировании сообщений Git будет запускать Emacs.
Если установить в этой настройке путь к какому-нибудь файлу в вашей системе, Git будет использовать содержимое этого файла в качестве сообщения по умолчанию при коммите. Например, предположим, что вы создали шаблонный файл $HOME/.gitmessage.txt, который выглядит следующим образом:
заголовок
что произошло
[карточка: X]
Чтобы попросить Git использовать это в качестве сообщения по умолчанию, которое будет появляться в вашем редакторе при выполнении git commit, задайте значение настройки commit.template:
$ git config --global commit.template $HOME/.gitmessage.txt
$ git commit
После этого, когда во время создания коммита запустится ваш редактор, в нём в качестве сообщения-заглушки будет находиться что-то вроде такого:
заголовок
что произошло
[карточка: X]
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: lib/test.rb
#
~
~
".git/COMMIT_EDITMSG" 14L, 297C
Если у вас существует определённая политика для сообщений коммитов, то задание шаблона, соответствующего этой политике, и настройка Git’а на использование его по умолчанию могут увеличить вероятность того, что этой политики будут придерживаться постоянно.
Настройка core.pager определяет, какой пейджер использовать при постраничном отображении вывода таких команд, как log и diff. Вы можете указать здесь more или свой любимый пейджер (по умолчанию используется less), или можно отключить его, указав пустую строку:
$ git config --global core.pager ''
Если это выполнить, Git будет выдавать весь вывод полностью для всех команд вне зависимости от того, насколько он большой.
Если вы делаете подписанные аннотированные метки (смотри главу 2), то, чтобы облегчить этот процесс, можно задать свой GPG-ключ для подписи в настройках. Задать ID своего ключа можно так:
$ git config --global user.signingkey <id-gpg-ключа>
Теперь, чтобы подписать метку, не обязательно каждый раз указывать свой ключ команде git tag:
$ git tag -s <имя-метки>
Чтобы Git не видел определённые файлы проекта как неотслеживаемые и не пытался добавить их в индекс при выполнении git add, можно задать для них шаблоны в файл .gitignore, как это описано главе 2. Однако, если вам необходим другой файл, который будет хранить эти или дополнительные значения вне вашего проекта, то вы можете указать Git’у расположение такого файла с помощью настройки core.excludesfile. Просто задайте там путь к файлу, в котором написано то же, что пишется в .gitignore.
Эта опция доступна только в Git 1.6.1 и более поздних. Если вы неправильно наберёте команду в Git’е, он выдаст что-то вроде этого:
$ git com
git: 'com' is not a git-command. See 'git --help'.
Did you mean this?
commit
Если установить help.autocorrect в 1, Git автоматически запустит нужную команду, если она была единственным вариантом при этом сценарии.
Git умеет раскрашивать свой вывод для терминала, что может помочь вам быстрее и легче визуально анализировать вывод. Множество опций в настройках помогут вам установить цвета в соответствии со своими предпочтениями.
Git автоматически раскрасит большую часть своего вывода, если вы его об этом попросите. Вы можете очень тонко задать, что вы хотите раскрасить и как. Но, чтобы просто включить весь предустановленный цветной вывод для терминала, установите color.ui в true:
$ git config --global color.ui true
Когда установлено это значение, Git раскрашивает свой вывод в случае, если вывод идёт на терминал. Другие доступные значения это: false, при котором вывод никогда не раскрашивается, и always, при котором цвета добавляются всегда, даже если вы перенаправляете вывод команд Git’а в файл или через конвейер другой команде.
Вам вряд ли понадобится использовать color.ui = always. В большинстве случаев, если вам нужны коды цветов в перенаправленном выводе, то вы можете просто передать команде флаг --color, чтобы заставить её добавить коды цветов. Настройка color.ui = true — это почти всегда именно то, что вам нужно.
color.*Если вам необходимо более точно задать какие команды и как должны быть раскрашены, то в Git’е есть возможность задать настройки цветов для каждой команды отдельно. Каждая из этих настроек может быть установлена в true, false или always:
color.branch
color.diff
color.interactive
color.status
Кроме того, каждая из этих настроек имеет свои поднастройки, которые можно использовать для задания определённого цвета для какой-то части вывода, если вы хотите перезадать цвета. Например, чтобы получить метаинформацию в выводе команды diff в синем цвете с чёрным фоном и жирным шрифтом, выполните
$ git config --global color.diff.meta “blue black bold”
Цвет может принимать любое из следующих значений: normal, black, red, green, yellow, blue, magenta, cyan и white. Если вы хотите задать атрибут вроде bold, как мы делали в предыдущем примере, то на выбор представлены: bold, dim, ul, blink и reverse.
Если вам это интересно, загляните в страницу руководства для git config, чтобы узнать обо всех доступных для конфигурации настройках.
Хоть в Git’е и есть внутренняя реализация diff, которой мы и пользовались до этого момента, вы можете заменить её внешней утилитой. И ещё вы можете установить графическую утилиту для разрешения конфликтов слияния, вместо того, чтобы разрешать конфликты вручную. Мы рассмотрим настройку Perforce Visual Merge Tool (P4Merge) в качестве замены diff и для разрешения конфликтов слияния, потому что это удобная графическая утилита и к тому же бесплатная.
Если вам захотелось её попробовать, то P4Merge работает на всех основных платформах, поэтому проблем с ней быть не должно. В примерах мы будем использовать пути к файлам, которые используются на Mac’е и Linux’е; для Windows вам надо заменить /usr/local/bin на тот путь к исполняемым файлам, который используется в вашей среде.
Скачать P4Merge можно здесь:
http://www.perforce.com/perforce/downloads/component.html
Для начала сделаем внешние сценарии-обёртки для запуска нужных команд. Я буду использовать Mac’овский путь к исполняемым файлам; для других систем это будет тот путь, куда установлен ваш файл p4merge. Сделайте для слияния сценарий-обёртку с именем extMerge, он будет вызывать бинарник со всеми переданными аргументами:
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/p4merge.app/Contents/MacOS/p4merge $*
Обёртка для команды diff проверяет, что ей было передано семь аргументов, и передаёт два из них вашему сценарию для слияния. По умолчанию Git передаёт следующие аргументы программе, выполняющей diff:
путь старый-файл старый-хеш старые-права новый-файл новый-хеш новые-права
Так как нам нужны только старый-файл и новый-файл, воспользуемся сценарием-обёрткой, чтобы передать только те аргументы, которые нам нужны:
$ cat /usr/local/bin/extDiff
#!/bin/sh
[ $# -eq 7 ] && /usr/local/bin/extMerge "$2" "$5"
Ещё следует убедиться, что наши сценарии имеют права на исполнение:
$ sudo chmod +x /usr/local/bin/extMerge
$ sudo chmod +x /usr/local/bin/extDiff
Теперь мы можем настроить свой конфигурационный файл на использование наших собственных утилит для разрешения слияний и diff’а. Для этого нам потребуется поменять несколько настроек: merge.tool, чтобы указать Git’у на то, какую стратегию использовать; mergetool.*.cmd, чтобы указать, как запустить команду; mergetool.trustExitCode, чтобы указать Git’у, можно ли по коду возврата определить, было разрешение конфликта слияния успешным или нет; и diff.external для того, чтобы задать команду, используемую для diff. Таким образом, вам надо либо выполнить четыре команды git config
$ git config --global merge.tool extMerge
$ git config --global mergetool.extMerge.cmd \
'extMerge "$BASE" "$LOCAL" "$REMOTE" "$MERGED"'
$ git config --global mergetool.trustExitCode false
$ git config --global diff.external extDiff
либо отредактировать свой файл ~/.gitconfig и добавить туда следующие строки:
[merge]
tool = extMerge
[mergetool "extMerge"]
cmd = extMerge \"$BASE\" \"$LOCAL\" \"$REMOTE\" \"$MERGED\"
trustExitCode = false
[diff]
external = extDiff
Если после того, как всё это настроено, вы выполните команду diff следующим образом:
$ git diff 32d1776b1^ 32d1776b1
то вместо того, чтобы получить вывод команды diff в терминал, Git запустит P4Merge, как это показано на рисунке 3-2.
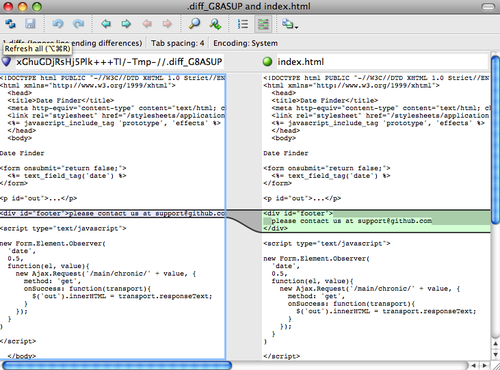
Рисунок 3-2. P4Merge.
Если при попытке слияния двух веток вы получите конфликт, запустите команду git mergetool — она запустит графическую утилиту P4Merge, с помощью которой вы сможете разрешить свои конфликты.
Что удобно в нашей настройке с обёртками, так это то, что вы с лёгкостью можете поменять утилиты для слияния и diff’а. Например, чтобы изменить свои утилиты extDiff и extMerge так, чтобы они использовали утилиту KDiff3, всё, что вам надо сделать, это отредактировать свой файл extMerge:
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/kdiff3.app/Contents/MacOS/kdiff3 $*
Теперь Git будет использовать утилиту KDiff3 для просмотра diff’ов и разрешения конфликтов слияния.
В Git’е уже есть предустановленные настройки для множества других утилит для разрешения слияний, для которых вам не надо полностью прописывать команду для запуска, а достаточно просто указать имя утилиты. К таким утилитам относятся: kdiff3, opendiff, tkdiff, meld, xxdiff, emerge, vimdiff и gvimdiff. Например, если вам неинтересно использовать KDiff3 для diff’ов, а хочется использовать его только для разрешения слияний, и команда kdiff3 находится в пути, то вы можете выполнить
$ git config --global merge.tool kdiff3
Если вместо настройки файлов extMerge и extDiff вы выполните эту команду, Git будет использовать KDiff3 для разрешения слияний и обычный свой инструмент diff для diff’ов.
Проблемы с форматированием и пробельными символами — одни из самых дурацких и трудноуловимых проблем из тех, с которыми сталкиваются многие разработчики при совместной работе над проектами, особенно если разработка ведётся на разных платформах. Очень просто внести малозаметные изменения с помощью пробельных символов при, например, подготовке патчей из-за того, что текстовые редакторы добавляют их без предупреждения, или в кросс-платформенных проектах Windows-программисты добавляют символы возврата каретки в конце изменяемых ими строк. В Git’е есть несколько опций для того, чтобы помочь с решением подобных проблем.
Если вы пишете код на Windows или пользуетесь другой системой, но работаете с людьми, которые пишут на Windows, то наверняка рано или поздно столкнётесь с проблемой конца строк. Она возникает из-за того, что Windows использует для переноса строк и символ возврата каретки, и символ перехода на новую строку, в то время как в системах Mac и Linux используется только символ перехода на новую строку. Это незначительное, но невероятно раздражающее обстоятельство при кросс-платформенной работе.
Git может справиться с этим, автоматически конвертируя CRLF-концы строк в LF при коммите и в обратную сторону при выгрузке кода из репозитория на файловую систему. Данную функциональность можно включить с помощью настройки core.autocrlf. Если вы используете Windows, установите настройку в true, тогда концы строк из LF будут сконвертированы в CRLF при выгрузке кода:
$ git config --global core.autocrlf true
Если вы сидите на Linux’е или Mac’е, где используются LF-концы строк, вам не надо, чтобы Git автоматически конвертировал их при выгрузке файлов из репозитория. Однако, если вдруг случайно кто-то добавил файл с CRLF-концами строк, то хотелось бы, чтобы Git исправил это. Можно указать Git’у, чтобы он конвертировал CRLF в LF только при коммитах, установив настройку core.autocrlf в input:
$ git config --global core.autocrlf input
Такая настройка даст вам CRLF-концы в выгруженном коде на Windows-системах и LF-концы на Mac’ах и Linux’е, и в репозитории.
Если вы Windows-программист, пишущий проект, предназначенный только для Windows, то можете отключить данную функциональность и записывать символы возврата каретки в репозиторий, установив значение настройки в false:
$ git config --global core.autocrlf false
Git заранее настроен на обнаружение и исправление некоторых проблем, связанных с пробелами. Он может находить четыре основные проблемы с пробелами — две из них по умолчанию отслеживаются, но могут быть выключены, и две по умолчанию не отслеживаются, но их можно включить.
Те две настройки, которые включены по умолчанию — это trailing-space, которая ищет пробелы в конце строк, и space-before-tab, которая ищет пробелы перед символами табуляции в начале строк.
Те две, которые по умолчанию выключены, но могут быть включены — это indent-with-non-tab, которая ищет строки, начинающиеся с восьми или более пробелов вместо символов табуляции, и cr-at-eol, которая сообщает Git’у, что символы возврата каретки в конце строк допустимы.
Вы можете указать Git’у, какие из этих настроек вы хотите включить, задав их в core.whitespace через запятую. Отключить настройку можно либо опустив её в списке, либо дописав знак - перед соответствующим значением. Например, если вы хотите установить все проверки, кроме cr-at-eol, то это можно сделать так:
$ git config --global core.whitespace \
trailing-space,space-before-tab,indent-with-non-tab
Git будет выявлять эти проблемы при запуске команды git diff и пытаться выделить их цветом так, чтобы можно было их исправить ещё до коммита. Кроме того, эти значения будут использоваться, чтобы помочь с применением патчей с помощью git apply. Когда будете принимать патч, можете попросить Git предупредить вас о наличии в патче заданных проблем с пробельными символами:
$ git apply --whitespace=warn <патч>
Или же Git может попытаться автоматически исправить проблему перед применением патча:
$ git apply --whitespace=fix <патч>
Данные настройки также относятся и к команде git rebase. Если вы вдруг сделали коммиты, в которых есть проблемы с пробельными символами, но ещё не отправили их на сервер, запустите rebase с опцией --whitespace=fix, чтобы Git автоматически исправил ошибки во время переписывания патчей.
Для серверной части Git’а доступно не так уж много настроек, но среди них есть несколько интересных, на которые следует обратить внимание.
По умолчанию Git не проверяет все отправленные на сервер объекты на целостность. Хотя Git и может проверять, что каждый объект всё ещё совпадает со своей контрольной суммой SHA-1 и указывает на допустимые объекты, по умолчанию Git не делает этого при каждом запуске команды push. Эта операция довольно затратна и может значительно увеличить время выполнения git push в зависимости от размера репозитория и количества отправляемых данных. Если вы хотите, чтобы Git проверял целостность объектов при каждой отправке данных, сделать это можно, установив receive.fsckObjects в true:
$ git config --system receive.fsckObjects true
Теперь Git, перед тем как принять новые данные от клиента, будет проверять целостность вашего репозитория, чтобы убедиться, что какой-нибудь неисправный клиент не внёс повреждённые данные.
Если вы переместили с помощью команды rebase уже отправленные на сервер коммиты и затем пытаетесь отправить их снова или, иначе, пытаетесь отправить коммит в такую удалённую ветку, которая не содержит коммит, на который на текущий момент указывает удалённая ветка — вам будет в этом отказано. Обычно это хорошая стратегия. Но в случае если вы переместили коммиты, хорошо понимая, зачем это вам нужно, вы можете вынудить Git обновить удалённую ветку, передав команде push флаг -f.
Чтобы отключить возможность принудительного обновления веток, задайте receive.denyNonFastForwards:
$ git config --system receive.denyNonFastForwards true
Есть ещё один способ сделать это — с помощью перехватчиков, работающих на приём (receive hooks), на стороне сервера, которые мы рассмотрим вкратце позднее. Такой подход позволит сделать более сложные вещи, такие как, например, запрет принудительных обновлений только для определённой группы пользователей.
Один из способов обойти политику denyNonFastForwards — это удалить ветку, а затем отправить новую ссылку на её место. В новых версиях Git’а (начиная с версии 1.6.1) вы можете установить receive.denyDeletes в true:
$ git config --system receive.denyDeletes true
Этим вы запретите удаление веток и меток с помощью команды push для всех сразу — ни один из пользователей не сможет этого сделать. Чтобы удалить ветку на сервере, вам придётся удалить файлы ссылок с сервера вручную. Также есть и другие более интересные способы добиться этого, но уже для отдельных пользователей с помощью ACL (списков контроля доступа), как мы увидим в конце этой главы.
Некоторые настройки могут быть заданы для отдельных путей, и тогда Git будет применять их только для некоторых подкаталогов или набора файлов. Такие настройки, специфичные по отношению к путям, называются атрибутами и задаются либо в файле .gitattributes в одном из каталогов проекта (обычно в корне), либо в файле .git/info/attributes, если вы не хотите, чтобы файл с атрибутами попал в коммит вместе с остальными файлами проекта.
Использование атрибутов позволяет, например, задать разные стратегии слияния для отдельных файлов или каталогов проекта, или объяснить Git’у, как сравнивать нетекстовые файлы, или сделать так, чтобы Git пропускал данные через фильтр перед тем, как выгрузить или записать данные в репозиторий. В этом разделе мы рассмотрим некоторые из доступных в Git’е атрибутов и рассмотрим несколько практических примеров их использования.
Есть один клёвый трюк, для которого можно использовать атрибуты — можно указать Git’у, какие файлы являются бинарными (в случае если по-другому определить это не получается), и дать ему специальные инструкции о том, как с этими файлами работать. Например, некоторые текстовые файлы могут быть машинными — генерируемыми программой — для них нет смысла вычислять дельты, в то время как для некоторых бинарных файлов получение дельт может быть полезным. Дальше мы увидим, как сказать Git’у, какие файлы какие.
Некоторые файлы выглядят как текстовые, но по существу должны рассматриваться как бинарные данные. Например, проекты Xcode на Mac’ах содержат файл, оканчивающийся на .pbxproj, который, по сути, является набором JSON-данных (текстовый формат данных для javascript), записываемым IDE, в котором сохраняются ваши настройки сборки и прочее. Хоть технически это и текстовый файл, потому что содержит только ASCII-символы, но нет смысла рассматривать его как таковой, потому что на самом деле это легковесная база данных — вы не сможете слить её содержимое, если два человека внесут в неё изменение, получение дельт тоже, как правило, ничем вам не поможет. Этот файл предназначается для обработки программой. По сути, лучше рассматривать этот файл как бинарный.
Чтобы заставить Git обращаться со всеми pbxproj-файлами как с бинарными, добавьте следующую строку в файл .gitattributes:
*.pbxproj -crlf -diff
Теперь Git не будет пытаться конвертировать CRLF-концы строк или исправлять проблемы с ними. Также он не будет пытаться получить дельту для изменений в этом файле при запуске git show или git diff в вашем проекте. В Git’е есть предустановленный макрос binary, который означает то же, что и -crlf -diff:
*.pbxproj binary
Функциональность атрибутов Git’а может быть использована для эффективного получения дельт бинарных файлов. Сделать это можно, объяснив Git’у, как сконвертировать ваши бинарные данные в текстовый формат, для которого можно выполнить сравнение с помощью обычного diff. Осталось только понять, как получить текстовое представление для бинарных данных. Идеальный вариант — найти подходящую утилиту для конвертирования нужного формата в текстовый вид. Но, к сожалению, получить хорошее текстовое представление можно только для весьма ограниченного набора бинарных форматов. Для большинства же бинарных форматов, например, для графических или аудио данных, получить читаемый текстовый вид не представляется возможным. Но если мы не можем получить текстовое представление содержимого, мы зачастую можем получить читаемое описание содержимого или метаданные. Метаданные не дают полное представление о содержимом файле, но, во всяком случае, это лучше чем ничего.
Далее мы рассмотрим оба подхода на примерах популярных бинарных форматов.
Замечание: Существуют разные виды бинарных файлов с текстовым содержимым, для которых вам, может быть, не удастся найти подходящий конвёртер. В данном случае вы можете попробовать вытащить текст с помощью утилиты strings. Некоторые из таких файлов могут использовать кодировку UTF-16 или могут быть написаны не в латинице, в таких файлах strings не найдёт ничего хорошего. Полезность strings может сильно варьироваться. Тем не менее, strings доступен на большинстве Mac- и Linux-систем, так что он может быть хорошим первым вариантом для того, чтобы сделать подобное со многими бинарными форматами.
Для начала мы используем описанный подход, чтобы решить одну из самых раздражающих проблем, известных человечеству: версионный контроль документов Word. Всем известно, что Word — это самый ужасающий из всех существующих редакторов, но, как ни странно, все им пользуются. Если вы хотите поместить документы Word под версионный контроль, вы можете запихнуть их в Git-репозиторий и время от времени делать коммиты. Но что в этом хорошего? Если вы запустите git diff как обычно, то увидите только что-то наподобие этого:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index 88839c4..4afcb7c 100644
Binary files a/chapter1.doc and b/chapter1.doc differ
У вас не получится сравнить две версии между собой, только если вы не выгрузите их обе и просмотрите их вручную, так? Оказывается, можно сделать это достаточно успешно, используя атрибуты Git’а. Поместите следующую строку в свой файл .gitattributes:
*.doc diff=word
Она говорит Git’у, что все файлы, соответствующие указанному шаблону (.doc) должны использовать фильтр “word” при попытке посмотреть дельту с изменениями. Что такое фильтр “word”? Нам нужно его изготовить. Сейчас мы настроим Git на использование программы catdoc, специально написанной для того, чтобы вытаскивать текстовую информацию из бинарных документов MS Word (скачать её можно по адресу http://www.45.free.net/~vitus/software/catdoc/), для конвертирования документов Word в читаемые текстовые файлы, которые Git затем правильно сравнит:
$ git config diff.word.textconv catdoc
Этой командой в свой .git/config вы добавите следующую секцию:
[diff "word"]
textconv = catdoc
Теперь Git знает, что если ему надо найти дельту между двумя снимками состояния, и какие-то их файлы заканчиваются на .doc, он должен прогнать эти файлы через фильтр “word”, который определён как программа catdoc. Так вы фактически сделаете текстовые версии своих Word-файлов перед тем, как получить для них дельту.
Рассмотрим пример. Я поместил главу 1 настоящей книги в Git, добавил немного текста в один параграф и сохранил документ. Затем я выполнил git diff, чтобы увидеть, что изменилось:
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index c1c8a0a..b93c9e4 100644
--- a/chapter1.doc
+++ b/chapter1.doc
@@ -128,7 +128,7 @@ and data size)
Since its birth in 2005, Git has evolved and matured to be easy to use
and yet retain these initial qualities. It’s incredibly fast, it’s
very efficient with large projects, and it has an incredible branching
-system for non-linear development.
+system for non-linear development (See Chapter 3).
Git коротко и ясно дал мне знать, что я добавил строку “(See Chapter 3)”, так оно и есть. Работает идеально.
Тот же подход, который мы использовали для файлов MS Word (*.doc), может быть использован и для текстовых файлов в формате OpenDocument, созданных в OpenOffice.org.
Добавим следующую строку в файл .gitattributes:
*.odt diff=odt
Теперь настроим фильтр odt в .git/config:
[diff "odt"]
binary = true
textconv = /usr/local/bin/odt-to-txt
Файлы в формате OpenDocument на самом деле являются запакованными zip’ом каталогами с множеством файлов (содержимое в XML-формате, таблицы стилей, изображения и т.д.). Мы напишем свой сценарий для извлечения содержимого и вывода его в виде обычного текста. Создайте файл /usr/local/bin/odt-to-txt (можете создать его в любом другом каталоге) со следующим содержимым:
#! /usr/bin/env perl
# Сценарий для конвертации OpenDocument Text (.odt) в обычный текст.
# Автор: Philipp Kempgen
if (! defined($ARGV[0])) {
print STDERR "Не задано имя файла!\n";
print STDERR "Использование: $0 имя файла\n";
exit 1;
}
my $content = '';
open my $fh, '-|', 'unzip', '-qq', '-p', $ARGV[0], 'content.xml' or die $!;
{
local $/ = undef; # считываем файл целиком
$content = <$fh>;
}
close $fh;
$_ = $content;
s/<text:span\b[^>]*>//g; # удаляем span'ы
s/<text:h\b[^>]*>/\n\n***** /g; # заголовки
s/<text:list-item\b[^>]*>\s*<text:p\b[^>]*>/\n -- /g; # элементы списков
s/<text:list\b[^>]*>/\n\n/g; # списки
s/<text:p\b[^>]*>/\n /g; # параграфы
s/<[^>]+>//g; # удаляем все XML-теги
s/\n{2,}/\n\n/g; # удаляем подряд идущие пустые строки
s/\A\n+//; # удаляем пустые строки в начале
print "\n", $_, "\n\n";
Сделайте его исполняемым
chmod +x /usr/local/bin/odt-to-txt
Теперь git diff сможет сказать вам, что изменилось в .odt файлах.
Ещё одна интересная проблема, которую можно решить таким способом, это сравнение файлов изображений. Один из способов сделать это — прогнать PNG-файлы через фильтр, извлекающий их EXIF-информацию — метаданные, которые дописываются в большинство форматов изображений. Если скачаете и установите программу exiftool, то сможете воспользоваться ею, чтобы извлечь из изображений текстовую информацию о метаданных, так чтобы diff хоть как-то показал вам текстовое представление произошедших изменений:
$ echo '*.png diff=exif' >> .gitattributes
$ git config diff.exif.textconv exiftool
Если вы замените в проекте изображение и запустите git diff, то получите что-то вроде такого:
diff --git a/image.png b/image.png
index 88839c4..4afcb7c 100644
--- a/image.png
+++ b/image.png
@@ -1,12 +1,12 @@
ExifTool Version Number : 7.74
-File Size : 70 kB
-File Modification Date/Time : 2009:04:17 10:12:35-07:00
+File Size : 94 kB
+File Modification Date/Time : 2009:04:21 07:02:43-07:00
File Type : PNG
MIME Type : image/png
-Image Width : 1058
-Image Height : 889
+Image Width : 1056
+Image Height : 827
Bit Depth : 8
Color Type : RGB with Alpha
Легко можно заметить, что размер файла, а также высота и ширина изображения поменялись.
Разработчики, привыкшие к SVN или CVS, часто хотят получить в Git’е возможность развёртывания ключа в стиле этих систем. Основная проблема с реализацией этой функциональности в Git’е это то, что нельзя записать в файл информацию о коммите после того, как коммит был сделан, так как Git сначала считает контрольную сумму для файла. Несмотря на это, вы можете вставлять текст в файл во время его выгрузки и удалять его перед добавлением в коммит. Атрибуты Git’а предлагают два варианта сделать это.
Во-первых, вы можете внедрять SHA-1-сумму блоба в поле $Id$ в файл автоматически. Если установить соответствующий атрибут для одного или нескольких файлов, то в следующий раз, когда вы будете выгружать данные из этой ветки, Git будет заменять это поле SHA-суммой блоба. Обратите внимание, что это SHA-1 не коммита, а самого блоба.
$ echo '*.txt ident' >> .gitattributes
$ echo '$Id$' > test.txt
$ git add test.txt
В следующий раз, когда вы будете выгружать этот файл, Git автоматически вставит в него SHA его блоба:
$ rm test.txt
$ git checkout -- test.txt
$ cat test.txt
$Id: 42812b7653c7b88933f8a9d6cad0ca16714b9bb3 $
Однако, такой результат мало применим. Если вы раньше пользовались развёртыванием ключа в CVS или Subversion, можете добавлять метку даты — SHA не особенно полезен, так как он довольно случаен, и к тому же, глядя на две SHA-суммы, никак не определить какая из них новее.
Как оказывается, можно написать свои собственные фильтры, которые будут делать подстановки в файлах при коммитах и выгрузке файлов. Для этого надо задать фильтры “clean” и “smudge”. В файле .gitattributes можно задать фильтр для определённых путей и затем установить сценарии, которые будут обрабатывать файлы непосредственно перед выгрузкой (“smudge”, см. рис. 3-3) и прямо перед коммитом (“clean”, см. рис. 3-4). Эти фильтры можно настроить на совершение абсолютно любых действий.
Рисунок 3-3. Фильтр “smudge” выполняется при checkout.
Рисунок 3-4. Фильтр “clean” выполняется при помещении файлов в индекс.
В сообщении первоначального коммита, добавляющего эту функциональность, дан простой пример того, как можно пропустить весь свой исходный код на C через программу indent перед коммитом. Сделать это можно, задав атрибут filter в файле .gitattributes так, чтобы он пропускал файлы *.c через фильтр “indent”:
*.c filter=indent
Затем укажите Git’у, что должен делать фильтр “indent” при smudge и clean:
$ git config --global filter.indent.clean indent
$ git config --global filter.indent.smudge cat
В нашем случае, когда вы будете делать коммит, содержащий файлы, соответствующие шаблону *.c, Git прогонит их через программу indent перед коммитом, а потом через программу cat перед тем как выгрузить их на диск. Программа cat, по сути, является холостой — она выдаёт те же данные, которые получила. Фактически эта комбинация профильтровывает все файлы с исходным кодом на C через indent перед тем, как сделать коммит.
Ещё один интересный пример — это развёртывание ключа $Date$ в стиле RCS. Чтобы сделать его правильно, нам понадобится небольшой сценарий, который принимает на вход имя файла, определяет дату последнего коммита в проекте и вставляет эту дату в наш файл. Вот небольшой сценарий на Ruby, который делает именно это:
#! /usr/bin/env ruby
data = STDIN.read
last_date = `git log --pretty=format:"%ad" -1`
puts data.gsub('$Date$', '$Date: ' + last_date.to_s + '$')
Всё, что делает этот сценарий, это получает дату последнего коммита с помощью команды git log, засовывает её во все строки $Date$, которые видит в stdin, и выводит результат — такое должно быть несложно реализовать на любом удобном вам языке. Давайте назовём этот файл expand_date и поместим в путь. Теперь в Git’е необходимо настроить фильтр (назовём его dater) и указать, что надо использовать фильтр expand_date при выполнении smudge во время выгрузки файлов. Воспользуемся регулярным выражением Perl, чтобы убрать изменения при коммите:
$ git config filter.dater.smudge expand_date
$ git config filter.dater.clean 'perl -pe "s/\\\$Date[^\\\$]*\\\$/\\\$Date\\\$/"'
Этот фрагмент кода на Perl’е вырезает всё, что находит в строке $Date$ так, чтобы вернуть всё в начальное состояние. Теперь, когда наш фильтр готов, можете протестировать его, создав файл с ключом $Date$ и установив для этого файла Git-атрибут, который задействует для него новый фильтр:
$ echo '# $Date$' > date_test.txt
$ echo 'date*.txt filter=dater' >> .gitattributes
Если мы сейчас добавим эти изменения в коммит и снова выгрузим файл, то мы увидим, что ключевое слово было заменено правильно:
$ git add date_test.txt .gitattributes
$ git commit -m "Testing date expansion in Git"
$ rm date_test.txt
$ git checkout date_test.txt
$ cat date_test.txt
# $Date: Tue Apr 21 07:26:52 2009 -0700$
Как видите, такая техника может быть весьма мощной для настройки проекта под свои нужды. Но вы должны быть осторожны, ибо файл .gitattributes вы добавите в коммит и будете его распространять вместе с проектом, а драйвер (в нашем случае dater) — нет. Так что не везде оно будет работать. Когда будете проектировать свои фильтры, постарайтесь сделать так, чтобы при возникновении в них ошибки проект не переставал работать правильно.
Ещё атрибуты в Git’е позволяют делать некоторые интересные вещи при экспортировании архива с проектом.
Вы можете попросить Git не экспортировать определённые файлы и каталоги при создании архива. Если у вас есть подкаталог или файл, который вы не желаете включать в архив, но хотите, чтобы в проекте он был, можете установить для такого файла атрибут export-ignore.
Например, скажем, у вас в подкаталоге test/ имеются некоторые тестовые файлы, и нет никакого смысла добавлять их в тарбол при экспорте проекта. Тогда добавим следующую строку в файл с Git-атрибутами:
test/ export-ignore
Теперь, если вы запустите git archive, чтобы создать тарбол с проектом, этот каталог в архив включён не будет.
Ещё одна вещь, которую можно сделать с архивами, — это сделать какую-нибудь простую подстановку ключевых слов. Git позволяет добавить в любой файл строку вида $Format:$ с любыми кодами форматирования, доступными в --pretty=format (многие из этих кодов мы рассматривали в главе 2). Например, если вам захотелось добавить в проект файл с именем LAST_COMMIT, в который при запуске git archive будет автоматически помещаться дата последнего коммита, то такой файл вы можете сделать следующим образом:
$ echo 'Last commit date: $Format:%cd$' > LAST_COMMIT
$ echo "LAST_COMMIT export-subst" >> .gitattributes
$ git add LAST_COMMIT .gitattributes
$ git commit -am 'adding LAST_COMMIT file for archives'
После запуска git archive этот файл у вас в архиве будет иметь содержимое следующего вида:
$ cat LAST_COMMIT
Last commit date: $Format:Tue Apr 21 08:38:48 2009 -0700$
Атрибуты Git’а могут также быть использованы для того, чтобы попросить Git использовать другие стратегии слияния для определённых файлов в проекте. Одна очень полезная возможность — это сказать Git’у, чтобы он не пытался слить некоторые файлы, если для них есть конфликт, а просто выбрал ваш вариант, предпочтя его чужому.
Это полезно в том случае, если ветка в вашем проекте разошлась с исходной, но вам всё же хотелось бы иметь возможность слить изменения из неё обратно, проигнорировав некоторые файлы. Скажем, у вас есть файл с настройками базы данных, который называется database.xml, и в двух ветках он разный, и вы хотите влить другую свою ветку, не трогая файл с настройками базы данных. Задайте атрибут следующим образом:
database.xml merge=ours
При вливании другой ветки, вместо конфликтов слияния для файла database.xml, вы увидите следующее:
$ git merge topic
Auto-merging database.xml
Merge made by recursive.
В данном случае database.xml остался в том варианте, в каком и был изначально.
Как и во многих других системах контроля версий, в Git’е есть возможность запускать собственные сценарии в те моменты, когда происходят некоторые важные действия. Существуют две группы подобных перехватчиков (hook): на стороне клиента и на стороне сервера. Перехватчики на стороне клиента предназначены для клиентских операций, таких как создание коммита и слияние. Перехватчики на стороне сервера нужны для серверных операций, таких как приём отправленных коммитов. Перехватчики могут быть использованы для выполнения самых различных задач. О некоторых из таких задач мы и поговорим.
Все перехватчики хранятся в подкаталоге hooks в Git-каталоге. В большинстве проектов это .git/hooks. По умолчанию Git заполняет этот каталог кучей примеров сценариев, многие из которых полезны сами по себе, но кроме того в них задокументированы входные значения для каждого из сценариев. Все эти примеры являются сценариями для командной оболочки с вкраплениями Perl’а, но вообще-то будет работать любой исполняемый сценарий с правильным именем — вы можете писать их на Ruby или Python или на чём-то ещё, что вам нравится. Эти файлы с примерами перехватчиков оканчиваются на .sample; вам надо их переименовать.
Чтобы активировать сценарий-перехватчик, положите файл в подкаталог hooks в Git-каталоге, дайте ему правильное имя и права на исполнение. С этого момента он будет вызываться. Основные имена перехватчиков мы сейчас рассмотрим.
Существует множество перехватчиков, работающих на стороне клиента. В этом разделе они поделены на перехватчики, используемые при работе над коммитами, сценарии, используемые в процессе работы с электронными письмами, и все остальные, работающие на стороне клиента.
Первые четыре перехватчика относятся к процессу создания коммита. Перехватчик pre-commit запускается первым, ещё до того, как вы наберёте сообщение коммита. Его используют для проверки снимка состояния перед тем, как сделать коммит, чтобы проверить, не забыли ли вы что-нибудь, чтобы убедиться, что вы запустили тесты, или проверить в коде ещё что-нибудь, что вам нужно. Завершение перехватчика с ненулевым кодом прерывает создание коммита, хотя вы можете обойти это с помощью git commit --no-verify. Можно, например, проверить стиль кодирования (запускать lint или что-нибудь аналогичное), проверить наличие пробельных символов в конце строк (перехватчик по умолчанию занимается именно этим) или проверить наличие необходимой документации для новых методов.
Перехватчик prepare-commit-msg запускается до появления редактора с сообщением коммита, но после создания сообщения по умолчанию. Он позволяет отредактировать сообщение по умолчанию перед тем, как автор коммита его увидит. У этого перехватчика есть несколько опций: путь к файлу, в котором сейчас хранится сообщение коммита, тип коммита и SHA-1 коммита (если в коммит вносится правка с помощью git commit --amend). Как правило, данный перехватчик не представляет пользы для обычных коммитов; он скорее хорош для коммитов с автогенерируемыми сообщениями, такими как шаблонные сообщения коммитов, коммиты-слияния, уплотнённые коммиты (squashed commits) и коммиты c исправлениями (amended commits). Данный перехватчик можно использовать в связке с шаблоном для коммита, чтобы программно добавлять в него информацию.
Перехватчик commit-msg принимает один параметр, и снова это путь к временному файлу, содержащему текущее сообщение коммита. Когда сценарий завершается с ненулевым кодом, Git прерывает процесс создания коммита. Так что можно использовать его для проверки состояния проекта или сообщений коммита перед тем, как его одобрить. В последнем разделе главы я продемонстрирую, как использовать данный перехватчик, чтобы проверить, что сообщение коммита соответствует требуемому шаблону.
После того, как весь процесс создания коммита завершён, запускается перехватчик post-commit. Он не принимает никаких параметров, но вы с лёгкостью можете получить последний коммит, выполнив git log -1 HEAD. Как правило, этот сценарий используется для уведомлений или чего-то в этом роде.
Сценарии на стороне клиента, предназначенные для запуска во время работы над коммитами, могут быть использованы при осуществлении практически любого типа рабочего процесса. Их часто используют, чтобы обеспечить соблюдение определённых стандартов, хотя важно отметить, что данные сценарии не передаются при клонировании. Вы можете принудить к соблюдению правил на стороне сервера, отвергая присланные коммиты, если они не подчиняются некоторым правилам, но использование данных сценариев на клиентской стороне полностью зависит только от разработчика. Итак, эти сценарии призваны помочь разработчикам, и это обязанность разработчиков установить и сопровождать их, хотя разработчики и имеют возможность в любой момент подменить их или модифицировать.
Для рабочих процессов, основанных на электронной почте, есть три специальных клиентских перехватчика. Все они вызываются командой git am, так что, если вы не пользуетесь этой командой в процессе своей работы, то можете смело переходить к следующему разделу. Если вы принимаете патчи, отправленные по e-mail и подготовленные с помощью git format-patch, то некоторые из них могут оказаться для вас полезными.
Первый запускаемый перехватчик — это applypatch-msg. Он принимает один аргумент — имя временного файла, содержащего предлагаемое сообщение коммита. Git прерывает наложение патча, если сценарий завершается с ненулевым кодом. Это может быть использовано для того, чтобы убедиться, что сообщение коммита правильно отформатировано или, чтобы нормализовать сообщение, отредактировав его на месте из сценария.
Следующий перехватчик, запускаемый во время наложения патчей с помощью git am — это pre-applypatch. У него нет аргументов, и он запускается после того, как патч наложен, поэтому его можно использовать для проверки снимка состояния перед созданием коммита. Можно запустить тесты или как-то ещё проверить рабочее дерево с помощью этого сценария. Если чего-то не хватает, или тесты не пройдены, выход с ненулевым кодом так же завершает сценарий git am без применения патча.
Последний перехватчик, запускаемый во время работы git am — это post-applypatch. Его можно использовать для уведомления группы или автора патча о том, что вы его применили. Этим сценарием процесс наложения патча остановить уже нельзя.
Перехватчик pre-rebase запускается перед перемещением чего-либо, и может остановить процесс перемещения, если завершится с ненулевым кодом. Этот перехватчик можно использовать, чтобы запретить перемещение любых уже отправленных коммитов. Пример перехватчика pre-rebase, устанавливаемый Git’ом, это и делает, хотя он предполагает, что ветка, в которой вы публикуете свои изменения, называется next. Вам, скорее всего, нужно будет заменить это имя на имя своей публичной стабильной ветки.
После успешного выполнения команды git checkout, запускается перехватчик post-checkout. Его можно использовать для того, чтобы правильно настроить рабочий каталог для своей проектной среды. Под этим может подразумеваться, например, перемещение в каталог больших бинарных файлов, которые вам не хочется включать под версионный контроль, автоматическое генерирование документации или что-то ещё в таком же духе.
И наконец, перехватчик post-merge запускается после успешного выполнения команды merge. Его можно использовать для восстановления в рабочем дереве данных, которые Git не может отследить, таких как информация о правах. Этот перехватчик может также проверить наличие внешних по отношению к контролируемым Git’ом файлов, которые вам нужно скопировать в каталог при изменениях рабочего дерева.
В дополнение к перехватчикам на стороне клиента вы как системный администратор можете задействовать пару важных перехватчиков на стороне сервера, чтобы навязать в своём проекте правила практически любого вида. Эти сценарии выполняются до и после отправки данных на сервер. Pre-перехватчики могут быть в любое время завершены с ненулевым кодом, чтобы отклонить присланные данные, а также вывести клиенту обратно сообщение об ошибке. Вы можете установить настолько сложные правила приёма данных, насколько захотите.
Первый сценарий, который выполняется при обработке отправленных клиентом данных, — это pre-receive. Он принимает на вход из stdin список отправленных ссылок; если он завершается с ненулевым кодом, ни одна из них не будет принята. Этот перехватчик можно использовать, чтобы, например, убедиться, что ни одна из обновлённых ссылок не выполняет ничего кроме перемотки, или, чтобы убедиться, что пользователь, запустивший git push, имеет права на создание, удаление или изменение для всех файлов, модифицируемых этим push’ем.
Перехватчик post-receive запускается после того, как весь процесс завершился, и может быть использован для обновления других сервисов или уведомления пользователей. Он получает на вход из stdin те же данные, что и перехватчик pre-receive. Примерами использования могут быть: отправка писем в рассылку, уведомление сервера непрерывной интеграции или обновление карточки (ticket) в системе отслеживания ошибок — вы можете даже анализировать сообщения коммитов, чтобы выяснить, нужно ли открыть, изменить или закрыть какие-то карточки. Этот сценарий не сможет остановить процесс приёма данных, но клиент не будет отключён до тех пор, пока процесс не завершится; так что будьте осторожны, если хотите сделать что-то, что может занять много времени.
Сценарий update очень похож на сценарий pre-receive, за исключением того, что он выполняется для каждой ветки, которую отправитель данных пытается обновить. Если отправитель пытается обновить несколько веток, то pre-receive выполнится только один раз, в то время как update выполнится по разу для каждой обновляемой ветки. Сценарий не считывает параметры из stdin, а принимает на вход три аргумента: имя ссылки (ветки), SHA-1, на которую ссылка указывала до запуска push, и тот SHA-1, который пользователь пытается отправить. Если сценарий update завершится с ненулевым кодом, то только одна ссылка будет отклонена, остальные ссылки всё ещё смогут быть обновлены.
В этом разделе мы используем ранее полученные знания для организации в Git’е такого рабочего процесса, который проверяет сообщения коммитов на соответствие заданному формату, из обновлений разрешает только перемотки и позволяет только определённым пользователям изменять определённые подкаталоги внутри проекта. Мы создадим клиентские сценарии, которые помогут разработчикам узнать, будет ли их push отклонён, и серверные сценарии, которые будут действительно вынуждать следовать установленным правилам.
Для их написания я использовал Ruby, и потому что это мой любимый язык сценариев, и потому что из всех языков сценариев он больше всего похож на псевдокод; таким образом, код должен быть вам понятен в общих чертах, даже если вы не пользуетесь Ruby. Однако любой язык сгодится. Все примеры перехватчиков, распространяемые вместе с Git’ом, написаны либо на Perl, либо на Bash, так что вы сможете просмотреть достаточно примеров перехватчиков на этих языках, заглянув в примеры.
Вся работа для сервера будет осуществляться в файле update из каталога hooks. Файл update запускается по разу для каждой отправленной ветки и принимает на вход ссылку, в которую сделано отправление, старую версию, на которой ветка находилась раньше, и новую присланную версию. Кроме того, вам будет доступно имя пользователя, приславшего данные, если push был выполнен по SSH. Если вы позволили подключаться всем под одним пользователем (например, “git”) с аутентификацией по открытому ключу, то вам может понадобиться создать для этого пользователя обёртку командной оболочки, которая на основе открытого ключа будет определять, какой пользователь осуществил подключение, и записывать этого пользователя в какой-нибудь переменной окружения. Тут я буду предполагать, что имя подключившегося пользователя находится в переменной окружения $USER, так что начнём наш сценарий со сбора всей необходимой информации:
#!/usr/bin/env ruby
$refname = ARGV[0]
$oldrev = ARGV[1]
$newrev = ARGV[2]
$user = ENV['USER']
puts "Enforcing Policies... \n(#{$refname}) (#{$oldrev[0,6]}) (#{$newrev[0,6]})"
Да, я использую глобальные переменные. Не судите строго — в таком виде получается нагляднее.
Первая наша задача — это заставить все сообщения коммитов обязательно придерживаться определённого формата. Просто чтобы было чем заняться, предположим, что каждое сообщение должно содержать строку вида “ref: 1234”, так как мы хотим, чтобы каждый коммит был связан с некоторым элементом в нашей системе с карточками. Нам необходимо просмотреть все присланные коммиты, выяснить, есть ли такая строка в сообщении коммита, и, если строка отсутствует в каком-либо из этих коммитов, то завершить сценарий с ненулевым кодом, чтобы push был отклонён.
Список значений SHA-1 для всех присланных коммитов можно получить, взяв значения $newrev и $oldrev и передав их служебной команде git rev-list. По сути, это команда git log, но по умолчанию она выводит только SHA-1 значения и больше ничего. Таким образом, чтобы получить список SHA для всех коммитов, сделанных между одним SHA коммита и другим, достаточно выполнить следующее:
$ git rev-list 538c33..d14fc7
d14fc7c847ab946ec39590d87783c69b031bdfb7
9f585da4401b0a3999e84113824d15245c13f0be
234071a1be950e2a8d078e6141f5cd20c1e61ad3
dfa04c9ef3d5197182f13fb5b9b1fb7717d2222a
17716ec0f1ff5c77eff40b7fe912f9f6cfd0e475
Можно взять этот вывод, пройти в цикле по SHA-хешам всех этих коммитов, беря их сообщения и проверяя с помощью регулярного выражения, совпадает ли сообщение с шаблоном.
Нам нужно выяснить, как из всех этих коммитов получить их сообщения, для того, чтобы их протестировать. Чтобы получить данные коммита в сыром виде, можно воспользоваться ещё одной служебной командой, которая называется git cat-file. Мы рассмотрим все эти служебные команды более подробно в главе 9, но пока что, вот, что эта команда нам выдала:
$ git cat-file commit ca82a6
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <schacon@gmail.com> 1205815931 -0700
committer Scott Chacon <schacon@gmail.com> 1240030591 -0700
changed the version number
Простой способ получить сообщение коммита для коммита, чьё значение SHA-1 известно, — это дойти в выводе команды git cat-file до первой пустой строки и взять всё, что идёт после неё. В Unix-системах это можно сделать с помощью команды sed:
$ git cat-file commit ca82a6 | sed '1,/^$/d'
changed the version number
Используйте приведённую ниже абракадабру, чтобы получить для каждого отправленного коммита его сообщение и выйти, если обнаружится, что что-то не соответствует требованиям. Если хотим отклонить отправленные данные, выходим с ненулевым кодом. Весь метод целиком выглядит следующим образом:
$regex = /\[ref: (\d+)\]/
# принуждает использовать особый формат сообщений
def check_message_format
missed_revs = `git rev-list #{$oldrev}..#{$newrev}`.split("\n")
missed_revs.each do |rev|
message = `git cat-file commit #{rev} | sed '1,/^$/d'`
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
end
end
end
check_message_format
Добавив это в свой сценарий update, мы запретим обновления, содержащие коммиты, сообщения которых не соблюдают наше правило.
Предположим, что нам хотелось бы добавить какой-нибудь механизм для использования списков контроля доступа (ACL), где указано, какие пользователи могут отправлять изменения и в какие части проекта. Несколько людей будут иметь полный доступ, а остальные будут иметь доступ на изменение только некоторых подкаталогов или отдельных файлов. Чтобы обеспечить выполнение такой политики, мы запишем правила в файл acl, который будет находиться в нашем “голом” репозитории на сервере. Нам нужно будет, чтобы перехватчик update брал эти правила, смотрел на то, какие файлы были изменены присланными коммитами, и определял, имеет ли пользователь, выполнивший push, право на обновление всех этих файлов.
Первое, что мы сделаем, — это напишем свой ACL. Мы сейчас будем использовать формат, очень похожий на механизм ACL в CVS. В нём используется последовательность строк, где первое поле — это avail или unavail, следующее поле — это разделённый запятыми список пользователей, для которых применяется правило, и последнее поле — это путь, к которому применяется правило (пропуск здесь означает открытый доступ). Все эти поля разделяются вертикальной чертой (|).
В нашем примере будет несколько администраторов, сколько-то занимающихся написанием документации с доступом к каталогу doc и один разработчик, который имеет доступ только к каталогам lib и tests, и наш файл acl будет выглядеть так:
avail|nickh,pjhyett,defunkt,tpw
avail|usinclair,cdickens,ebronte|doc
avail|schacon|lib
avail|schacon|tests
Начнём со считывания этих данных в какую-нибудь пригодную для использования структуру. В нашем случае, чтобы не усложнять пример, мы будем применять только директивы avail. Вот метод, который даёт нам ассоциативный массив, где ключом является имя пользователя, а значением — массив путей, для которых пользователь имеет доступ на запись:
def get_acl_access_data(acl_file)
# считывание данных ACL
acl_file = File.read(acl_file).split("\n").reject { |line| line == '' }
access = {}
acl_file.each do |line|
avail, users, path = line.split('|')
next unless avail == 'avail'
users.split(',').each do |user|
access[user] ||= []
access[user] << path
end
end
access
end
Для рассмотренного ранее ACL-файла, метод get_acl_access_data вернёт структуру данных следующего вида:
{"defunkt"=>[nil],
"tpw"=>[nil],
"nickh"=>[nil],
"pjhyett"=>[nil],
"schacon"=>["lib", "tests"],
"cdickens"=>["doc"],
"usinclair"=>["doc"],
"ebronte"=>["doc"]}
Теперь, когда мы разобрались с правами, нам нужно выяснить, какие пути изменяются присланными коммитами, чтобы можно было убедиться, что пользователь, выполнивший push, имеет ко всем ним доступ.
Мы довольно легко можем определить, какие файлы были изменены в одном коммите, с помощью опции --name-only для команды git log (мы упоминали о ней в главе 2):
$ git log -1 --name-only --pretty=format:'' 9f585d
README
lib/test.rb
Если мы воспользуемся ACL-структурой, полученной из метода get_acl_access_data, и сверим её со списком файлов для каждого коммита, то мы сможем определить, имеет ли пользователь право на отправку своих коммитов:
# некоторые подкаталоги в проекте разрешено модифицировать только определённым пользователям
def check_directory_perms
access = get_acl_access_data('acl')
# проверим, что никто не пытается прислать чего-то, что ему нельзя
new_commits = `git rev-list #{$oldrev}..#{$newrev}`.split("\n")
new_commits.each do |rev|
files_modified = `git log -1 --name-only --pretty=format:'' #{rev}`.split("\n")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path || # пользователь имеет полный доступ
(path.index(access_path) == 0) # доступ к этому пути
has_file_access = true
end
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
end
check_directory_perms
Большую часть этого кода должно быть не сложно понять. Мы получаем список присланных на сервер коммитов с помощью git rev-list. Затем для каждого из них мы узнаём, какие файлы были изменены, и убеждаемся, что пользователь, сделавший push, имеет доступ ко всем изменённым путям. Один Ruby’изм, который может быть непонятен — это path.index(access_path) == 0. Это условие верно, если path начинается с access_path — оно гарантирует, что access_path — это не просто один из разрешённых путей, а что каждый путь, к которому запрашивается доступ, начинается с одного из разрешённых путей.
Теперь наши пользователи не смогут отправить никаких коммитов с плохо отформатированными сообщениями и не смогут изменить файлы вне предназначенных для них путей.
Единственное, что нам осталось — это оставить доступными только обновления-перемотки. Чтобы добиться этого, можно просто задать настройки receive.denyDeletes и receive.denyNonFastForwards. Но осуществление этого с помощью перехватчика также будет работать, и к тому же вы сможете изменить его так, чтобы запрет действовал только для определённых пользователей, или ещё как-то, как вам захочется.
Логика здесь такая — мы проверяем, есть ли такие коммиты, которые достижимы из старой версии и не достижимы из новой. Если таких нет, то сделанный push был перемоткой; в противном случае мы его запрещаем:
# разрешаем только обновления-перемотки
def check_fast_forward
missed_refs = `git rev-list #{$newrev}..#{$oldrev}`
missed_ref_count = missed_refs.split("\n").size
if missed_ref_count > 0
puts "[POLICY] Cannot push a non fast-forward reference"
exit 1
end
end
check_fast_forward
Всё готово. Если вы выполните chmod u+x .git/hooks/update (а это тот файл, в который вы должны были поместить весь наш код) и затем попытаетесь отправить ссылку, для которой нельзя выполнить перемотку, то вы получите что-то типа такого:
$ git push -f origin master
Counting objects: 5, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 323 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
Enforcing Policies...
(refs/heads/master) (8338c5) (c5b616)
[POLICY] Cannot push a non fast-forward reference
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
Тут есть пара интересных моментов. Во-первых, когда перехватчик начинает свою работу, мы видим это:
Enforcing Policies...
(refs/heads/master) (8338c5) (c56860)
Обратите внимание, что мы выводили это в stdout в самом начале нашего сценария update. Важно отметить, что всё, что сценарий выводит в stdout, будет передано клиенту.
Следующая вещь, которую мы видим, это сообщение об ошибке:
[POLICY] Cannot push a non fast-forward reference
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
Первую строку напечатали мы, а в остальных двух Git сообщает, что сценарий update завершился с ненулевым кодом, и это именно то, что отклонило ваш push. И, наконец, мы видим это:
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
Сообщение “remote rejected” будет появляться для каждой отклонённой перехватчиком ссылки. Оно сообщает нам, что ссылка была отклонена именно из-за сбоя в перехватчике.
Кроме того, при отсутствии отметки “ref” в каком-либо из коммитов, вы увидите сообщение об ошибке, которое мы для этого напечатали.
[POLICY] Your message is not formatted correctly
Или если кто-то попытается отредактировать файл, не имея к нему доступа, то, отправив коммит с этими изменениями, он получит похожее сообщение. Например, если человек, пишущий документацию, попытается отправить коммит, вносящий изменения в файлы каталога lib, то увидит:
[POLICY] You do not have access to push to lib/test.rb
Вот и всё. С этого момента, до тех пор пока сценарий update находится на своём месте и имеет права на исполнение, репозиторий никогда не будет откатан назад, в нём никогда не будет коммитов с сообщениями без вашего паттерна, и пользователи будут ограничены в доступе к файлам.
Обратная сторона такого подхода — это многочисленные жалобы, которые неизбежно появятся, когда отправленные пользователями коммиты будут отклонены. Когда чью-то тщательно оформленную работу отклоняют в последний момент, этот человек может быть сильно расстроен и смущён. Мало того, ему придётся отредактировать свою историю, чтобы откорректировать её, а это обычно не для слабонервных.
Решение данной проблемы — предоставить пользователям какие-нибудь перехватчики, которые будут работать на стороне пользователя и будут сообщать ему, если он делает что-то, что, скорее всего, будет отклонено. При таком подходе, пользователи смогут исправить любые проблемы до создания коммита и до того, как эти проблемы станет сложно исправить. Так как перехватчики не пересылаются при клонировании проекта, вам придётся распространять эти сценарии каким-то другим способом и потом сделать так, чтобы ваши пользователи скопировали их в свой каталог .git/hooks и сделали их исполняемыми. Эти перехватчики можно поместить в свой проект или даже в отдельный проект, но способа установить их автоматически не существует.
Для начала, перед записью каждого коммита нам надо проверить его сообщение, чтобы быть уверенным, что сервер не отклонит изменения из-за плохо отформатированного сообщения коммита. Чтобы сделать это, добавим перехватчик commit-msg. Если мы сможем прочитать сообщение из файла, переданного в качестве первого аргумента, и сравнить его с шаблоном, то можно заставить Git прервать создание коммита при обнаружении несовпадения:
#!/usr/bin/env ruby
message_file = ARGV[0]
message = File.read(message_file)
$regex = /\[ref: (\d+)\]/
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
end
Если этот сценарий находится на своём месте (в .git/hooks/commit-msg) и имеет права на исполнение, то при создании коммита с неправильно оформленным сообщением вы увидите это:
$ git commit -am 'test'
[POLICY] Your message is not formatted correctly
В этом случае коммит не был завершён. Однако, когда сообщение содержит правильный шаблон, Git позволяет создать коммит:
$ git commit -am 'test [ref: 132]'
[master e05c914] test [ref: 132]
1 files changed, 1 insertions(+), 0 deletions(-)
Далее мы хотим убедиться, что пользователь не модифицирует файлы вне своей области, заданной в ACL. Если в проекте в каталоге .git уже есть копия файла acl, который мы использовали ранее, то сценарий pre-commit следующего вида применит эти ограничения:
#!/usr/bin/env ruby
$user = ENV['USER']
# [ insert acl_access_data method from above ]
# некоторые подкаталоги в проекте разрешено модифицировать только определённым пользователям
def check_directory_perms
access = get_acl_access_data('.git/acl')
files_modified = `git diff-index --cached --name-only HEAD`.split("\n")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path || (path.index(access_path) == 0)
has_file_access = true
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
check_directory_perms
Это примерно тот же сценарий, что и на стороне сервера, но с двумя важными отличиями. Первое — файл acl находится в другом месте, так как этот сценарий теперь запускается из рабочего каталога, а не из Git-каталога. Нужно изменить путь к ACL-файлу с этого:
access = get_acl_access_data('acl')
на этот:
access = get_acl_access_data('.git/acl')
Другое важное отличие — это способ получения списка изменённых файлов. Так как метод, действующий на стороне сервера, смотрит в лог коммитов, а сейчас коммит ещё не был записан, нам надо получить список файлов из индекса. Вместо
files_modified = `git log -1 --name-only --pretty=format:'' #{ref}`
мы должны использовать
files_modified = `git diff-index --cached --name-only HEAD`
Но это единственные два отличия — во всём остальном этот сценарий работает точно так же. Но надо предупредить, что он предполагает, что локально вы работаете под тем же пользователем, от имени которого отправляете изменения на удалённый сервер. Если это не так, то вам необходимо задать переменную $user вручную.
Последнее, что нам нужно сделать, — это проверить, что пользователь не пытается отправить ссылки не с перемоткой, но это случается не так часто. Чтобы получились ссылки, не являющиеся перемоткой, надо либо переместить ветку за уже отправленный коммит, либо попытаться отправить другую локальную ветку в ту же самую удалённую ветку.
Так как сервер в любом случае сообщит вам о том, что нельзя отправлять обновления, не являющиеся перемоткой, а перехватчик запрещает принудительные push‘и, единственная оплошность, которую вы можете попробовать предотвратить, это перемещение коммитов, которые уже были отправлены на сервер.
Вот пример сценария pre-rebase, который это проверяет. Он принимает на вход список всех коммитов, которые вы собираетесь переписать, и проверяет, нет ли их в какой-нибудь из ваших удалённых веток. Если найдётся такой коммит, который достижим из одной из удалённых веток, сценарий прервёт выполнение перемещения:
#!/usr/bin/env ruby
base_branch = ARGV[0]
if ARGV[1]
topic_branch = ARGV[1]
else
topic_branch = "HEAD"
end
target_shas = `git rev-list #{base_branch}..#{topic_branch}`.split("\n")
remote_refs = `git branch -r`.split("\n").map { |r| r.strip }
target_shas.each do |sha|
remote_refs.each do |remote_ref|
shas_pushed = `git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}`
if shas_pushed.split(“\n”).include?(sha)
puts "[POLICY] Commit #{sha} has already been pushed to #{remote_ref}"
exit 1
end
end
end
Этот сценарий использует синтаксис, который мы не рассматривали в разделе “Выбор ревизии” в главе 6. Мы получили список коммитов, которые уже были отправлены на сервер, выполнив это:
git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}
Запись SHA^@ означает всех родителей указанного коммита. Мы ищем какой-нибудь коммит, который достижим из последнего коммита в удалённой ветке и не достижим ни из одного из родителей какого-либо SHA, который вы пытаетесь отправить на сервер — это значит, что это перемотка.
Главный недостаток такого подхода — это то, что проверка может быть очень медленной и зачастую избыточной — если вы не пытаетесь отправить данные принудительно с помощью -f, сервер и так выдаст предупреждение и не примет данные. Однако, это интересное упражнение и теоретически может помочь вам избежать перемещения, к которому потом придётся вернуться, чтобы исправить.
Мы рассмотрели большинство основных способов настройки клиента и сервера Git’а с тем, чтобы он был максимально удобен для ваших проектов и при вашей организации рабочего процесса. Мы узнали о всевозможных настройках, атрибутах файлов и о перехватчиках событий, а также рассмотрели пример настройки сервера с соблюдением политики. Теперь вам должно быть по плечу заставить Git подстроиться под практически любой тип рабочего процесса, который можно вообразить.