

В рамках первой лекции мы познакомимся с тем, что такое системы управления версиями (мне хотелось рефлекторно в конце добавить кода, но это не так. Об этом чуть позже). Сначала мы расскажем о происхождении инструментов для контроля версий, узнаем, какие системы управления версиями сейчас популярны и в чем у них основные различия. Безусловно, рассмотрим, почему именно GIT и познакомимся с ним. Разберемся, как начать работу с Git’ом — как установить и запустить Git на вашей машине и наконец, как настроить его так, чтоб можно было приступить к работе. К концу этой лекции вы будете понимать, зачем Git вообще сделан, почему вам стоит им пользоваться, и будете готовы начать с ним работать.
Что такое контроль версий, и зачем он вам нужен?
Система контроля версий (СКВ) — это система, регистрирующая изменения в одном или нескольких файлах с тем, чтобы в дальнейшем была возможность вернуться к определённым старым версиям этих файлов.
В последнее время файлы являются конечным результатом для многих профессий, здесь можно назвать, для примера, писательскую деятельность, научные работы и конечно разработку программного обеспечения. Тратится много времени и сил на разработку и поддержку этих файлов и никто не хочет, чтобы пришлось тратить еще больше времени и сил на восстановление данных потерянных в результате каких-либо изменений.
Представим, что программист разрабатывает проект состоящий из одного небольшого файла (кстати, пример вполне реальный, не синтетический). После выпуска первой версии проекта перед ним встает непростой выбор: необходимо исправлять проблемы о которых сообщают пользователи первой версии и, в тоже время, разрабатывать что-то новое для второй. Даже если надо просто исправлять возникающие проблемы, то велика вероятность, что после какого-либо изменения проект перестает работать, и надо определить, что было изменено, чтобы было проще локализовать проблему. Также желательно вести какой-то журнал внесенных изменений и исправлений, чтобы не делать несколько раз одну и ту же работу.
В простейшем случае вышеприведенную проблему можно решить хранением нескольких копий файлов, например, один для исправления ошибок в первой версии проекта и второй для новых изменений. Так как изменения обычно не очень большие по сравнению с размером файла, то можно хранить только измененные строки используя утилиту diff и позже объединять их с помощью утилиты patch. Но что если проект состоит из нескольких тысяч файлов и над ним работает сотня человек? Если в этом случае использовать метод с хранением отдельных копий файлов (или даже только изменений) то проект застопорится очень быстро.
Для примеров мы будем использовать исходные коды программ, но на самом деле под версионный контроль можно поместить файлы практически любого типа.
Если вы графический или веб-дизайнер и хотели бы хранить каждую версию изображения или макета — а этого вам наверняка хочется — то пользоваться системой контроля версий будет очень мудрым решением. СКВ даёт возможность возвращать отдельные файлы к прежнему виду, возвращать к прежнему состоянию весь проект, просматривать происходящие со временем изменения, определять, кто последним вносил изменения во внезапно переставший работать модуль, кто и когда внёс в код какую-то ошибку, и многое другое. Вообще, если, пользуясь СКВ, вы всё испортите или потеряете файлы, всё можно будет легко восстановить. Вдобавок, накладные расходы за всё, что вы получаете, будут очень маленькими.
Как уже говорилось ранее - один из примеров локальной СУВ предельно прост: многие предпочитают контролировать версии, просто копируя файлы в другой каталог (как правило добавляя текущую дату к названию каталога). Такой подход очень распространён, потому что прост, но он и чаще даёт сбои. Очень легко забыть, что ты не в том каталоге, и случайно изменить не тот файл, либо скопировать файлы не туда, куда хотел, и затереть нужные файлы.
Чтобы решить эту проблему, программисты уже давно разработали локальные СКВ с простой базой данных, в которой хранятся все изменения нужных файлов
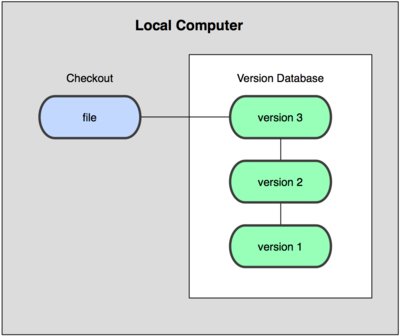
Рисунок 1-1. Схема локальной СКВ.
Одной из наиболее популярных СКВ такого типа является RCS (Revision Control System, Система контроля ревизий), которая до сих пор устанавливается на многие компьютеры. Даже в современной операционной системе Mac OS X утилита rcs устанавливается вместе с Developer Tools.
RCS была разработана в начале 1980-х годов Вальтером Тичи (Walter F. Tichy). Система позволяет хранить версии только одного файла, таким образом управлять несколькими файлами приходится вручную. Для каждого файла находящегося под контролем системы информация о версиях хранится в специальном файле с именем оригинального файла к которому в конце добавлены символы ',v'. Например для файла file.txt версии будут храниться в файле file.txt,v. Эта утилита основана на работе с наборами патчей между парами версий (патч — файл, описывающий различие между файлами). Это позволяет пересоздать любой файл на любой момент времени, последовательно накладывая патчи. Для хранения версий система использует утилиту diff.
Рассмотрим пример сессии с RCS. Когда мы хотим положить файл под контроль RCS мы используем команду ci (от check-in, регистрировать):
$ ci file.txt
Данная команда создает файл file.txt,v и удаляет исходный файл file.txt (если не сказано этого не делать). Также эта команда запрашивает описание для всех хранимых версий. Так как исходный файл был удален системой мы должны запросить его обратно, что бы вносить изменения. Для этого мы используем команду co (от check-out, контролировать):
$ co file.txt
Эта команда вынимает последнюю версию нашего файла из file.txt,v. Теперь мы можем отредактировать файл file.txt и после того как закончим изменения опять выполнить команду ci для того что бы сохранить новую измененную версию файла:
$ ci file.txt
При выполнении этой команды система запросит у нас описание изменений и затем сохранит новую версию файла.
Хотя RCS соответствует минимальным требованиям к системе контроля версий она имеет следующие основные недостатки, которые также послужили стимулом для создания следующей рассматриваемой системы:
Следующей основной проблемой оказалась необходимость сотрудничать с разработчиками за другими компьютерами. Чтобы решить её, были созданы централизованные системы контроля версий (ЦСКВ). В таких системах, например CVS, Subversion и Perforce, есть центральный сервер, на котором хранятся все файлы под версионным контролем, и ряд клиентов, которые получают копии файлов из него. Много лет это было стандартом для систем контроля версий.
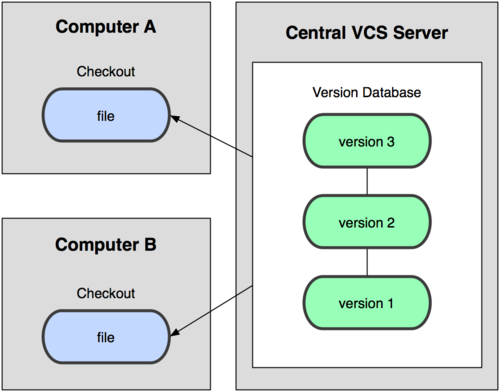
Рисунок 1-2. Схема централизованного контроля версий.
Такой подход имеет множество преимуществ, особенно над локальными СКВ. К примеру, все знают, кто и чем занимается в проекте. У администраторов есть чёткий контроль над тем, кто и что может делать, и, конечно, администрировать ЦСКВ намного легче, чем локальные базы на каждом клиенте.
Однако при таком подходе есть и несколько серьёзных недостатков. Наиболее очевидный — централизованный сервер является уязвимым местом всей системы. Если сервер выключается на час, то в течение часа разработчики не могут взаимодействовать, и никто не может сохранить новой версии своей работы. Если же повреждается диск с центральной базой данных и нет резервной копии, вы теряете абсолютно всё — всю историю проекта, разве что за исключением нескольких рабочих версий, сохранившихся на рабочих машинах пользователей.
CVS (Concurrent Versions System, Система совместных версий) пока остается самой широко используемой системой, но быстро теряет свою популярность из-за недостатков которые я рассмотрю ниже. Дик Грун (Dick Grune) разработал CVS в середине 1980-х. Для хранения индивидуальных файлов CVS (также как и RCS) использует файлы в RCS формате, но позволяет управлять группами файлов расположенных в директориях. Также CVS использует клиент-сервер архитектуру в которой вся информация о версиях хранится на сервере. Использование клиент-сервер архитектуры позволяет использовать CVS даже географически распределенным командами пользователей где каждый пользователь имеет свой рабочий директорий с копией проекта.
Как следует из названия пользователи могут использовать систему совместно. Возможные конфликты при изменении одного и того же файла разрешаются тем, что система позволяет вносить изменения только в самую последнюю версию файла. Таким образом всегда рекомендуется перед заливкой своих изменений обновлять свою рабочую копию файлов на случай возможных конфликтующих изменений. При обновлении система вносит изменения в рабочую копию автоматически и только в случае конфликтующих изменений в одном из мест файла требуется ручное исправление места конфликта.
CVS также позволяет вести несколько линий разработки проекта с помощью ветвей (branches) разработки. Таким образом, как уже упоминалось выше, можно исправлять ошибки в первой версии проекта и параллельно разрабатывать новую функциональность.
Рассмотрим небольшой пример сессии с CVS. Прежде всего надо импортировать проект в CVS, это делается с помощью команды import (импортировать):
$ cd some-project
$ cvs import -m "New project" path-in-repository none start
Здесь опция -m позволяет задать описание изменений прямо в командной строке и если ее опустить, то будет вызван текстовый редактор. Далее указывается путь по которому проект будет храниться в репозитории (path-in-repository в нашем случае) и после него две метки: метка разработчика (может пригодится в случае использования CVS для работы над проектами разработанными кем-то другим) и метка проекта.
После того как мы залили наш проект в репозиторий необходимо создать новый директорий в котором будет находится рабочая копия проекта под контролем CVS и загрузить проект с помощью команды checkout (контроль), или сокращенно co:
$ cd some-working-dir
$ cvs checkout path-in-repository
Для команды checkout мы указываем путь к нашему проекту в репозитории который мы указывали выше в команде import.
Теперь мы можем внести в проект изменения и залить их в репозиторий с помощью команды commit (совершить изменения), или сокращенно ci:
$ cvs commit -m "Some changes"
Также как и для команды import мы указываем комментарий к нашим изменениям с помощью опции -m.
Если мы хотим обновить наш рабочий директорий новой версией проекта из репозитория мы используем команду update (обновить), или сокращенно up:
$ cvs update
CVS использовалась большим количеством проектов, но конечно не была лишена недостатков которые позднее привели к появлению следующей рассматриваемой системы. Рассмотрим основные недостатки:
cvs remove и затем добавить с его новым именем с помощью команды cvs add;Subversion (SVN) был разработан в 2000 году по инициативе фирмы CollabNet. SVN изначально разрабатывался как “лучший CVS” и основной задачей разработчиков было исправление ошибок допущенных в дизайне CVS при сохранении похожего интерфейса. SVN также как и CVS использует клиент-сервер архитектуру. Из наиболее значительных изменений по сравнению с CVS можно отметить:
commit). В случае если обработка коммита была прервана не будет внесено никаких изменений.Рассмотрим примеры команд, хотя надо заметить, что большинство из них практически повторяют команды CVS. Что бы использовать проект с SVN его надо сначала импортировать в репозиторий с помощью команды import (импортировать):
$ cd some-project
$ svn import -m "New project" path-in-repository
В отличие от CVS не нужно указывать метки разработчика и проекта, которые не часто использовались на практике.
Теперь нам нужно создать рабочую копию проекта с помощью команды checkout (контроль), или co:
$ cd some-working-dir
$ svn checkout path-in-repository
После внесения изменений мы используем команду commit (совершить изменения) , или ci для сохранения изменений в репозитории:
$ svn commit -m "Some changes"
И для обновления рабочей копии проекта используется команда update (обновить), или up:
$ svn up
И в этой ситуации в игру вступают распределённые системы контроля версий (РСКВ). В таких системах как Git, Mercurial, Bazaar или Darcs клиенты не просто выгружают последние версии файлов, а полностью копируют весь репозиторий. Поэтому в случае, когда “умирает” сервер, через который шла работа, любой клиентский репозиторий может быть скопирован обратно на сервер, чтобы восстановить базу данных. Каждый раз, когда клиент забирает свежую версию файлов, он создаёт себе полную копию всех данных.
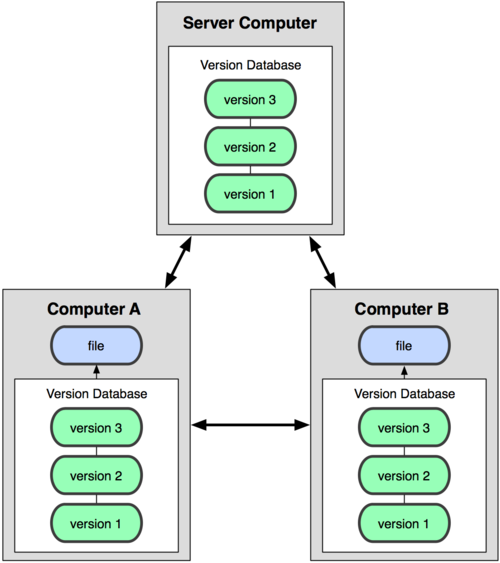
Рисунок 1-3. Схема распределённой системы контроля версий.
Кроме того, в большей части этих систем можно работать с несколькими удалёнными репозиториями, таким образом, можно одновременно работать по-разному с разными группами людей в рамках одного проекта. Так, в одном проекте можно одновременно вести несколько типов рабочих процессов, что не возможно в централизованных системах.
Как следует из названия одна из основных идей распределенных систем — это отсутствие четко выделенного центрального хранилища версий - репозитория. В случае распределенных систем набор версий может быть полностью, или частично распределен между различными хранилищами, в том числе и удаленными. Такая модель отлично вписывается в работу распределенных команд, например, распределенной по всему миру команды разработчиков работающих над одним проектом с открытым исходным кодом. Разработчик такой команды может скачать себе всю информацию по версиям и после этого работать только на локальной машине. Как только будет достигнут результат одного из этапов работы, изменения могут быть залиты в один из центральных репозиториев или, опубликованы для просмотра на сайте разработчика, или в почтовой рассылке. Другие участники проекта, в свою очередь, смогут обновить свою копию хранилища версий новыми изменениями, или попробовать опубликованные изменения на отдельной, тестовой ветке разработки. К сожалению, без хорошей организации проекта отсутствие одного центрального хранилища может быть минусом распределенных систем. Если в случае централизованных систем всегда есть один общий репозиторий откуда можно получить последнюю версию проекта, то в случае распределенных систем нужно организационно решить какая из веток проекта будет основной.
Почему распределенная система контроля версий может быть интересна кому-то, кто уже использует централизованную систему - такую как Subversion? Любая работа подразумевает принятие решений, и в большинстве случаев необходимо пробовать различные варианты: при работе с системами контроля версий для рассмотрения различных вариантов и работы над большими изменениями служат ветки разработки. И хотя это достаточно естественная концепция, пользоваться ей в Subversion достаточно не просто. Тем более, все усложняется в случае множественных последовательных объединений с одной ветки на другую — в этом случае нужно безошибочно указывать начальные и конечные версии каждого изменения, что бы избежать конфликтов и ошибок. Для распределенных систем контроля версий ветки разработки являются одной из основополагающих концепций — в большинстве случаев каждая копия хранилища версий является веткой разработки. Таким образом, механизм объединения изменений с одной ветки на другую в случае распределенных систем является одним из основных, что позволяет пользователям прикладывать меньше усилий при пользовании системой.
Как и многие замечательные вещи, Git начинался с, в некотором роде, разрушения во имя созидания и жарких споров. Ядро Linux — действительно очень большой открытый проект. Бо́льшую часть существования ядра Linux (1991-2002) изменения к нему распространялись в виде патчей и заархивированных файлов. В 2002 году проект перешёл на проприетарную РСКВ BitKeeper.
В 2005 году отношения между сообществом разработчиков ядра Linux и компанией, разрабатывавшей BitKeeper, испортились, и право бесплатного пользования продуктом было отменено. Это подтолкнуло разработчиков Linux (и в частности Линуса Торвальдса, создателя Linux) разработать собственную систему, основываясь на опыте, полученном за время использования BitKeeper. Основные требования к новой системе были следующими:
С момента рождения в 2005 году Git развивался и эволюционировал, становясь проще и удобнее в использовании, сохраняя при этом свои первоначальные качества. Он невероятно быстр, очень эффективен для больших проектов, а также обладает превосходной системой ветвления для нелинейной разработки.
Так что же такое Git в двух словах? Эту часть важно усвоить, поскольку если вы поймёте, что такое Git, и каковы принципы его работы, вам будет гораздо проще пользоваться им эффективно. Изучая Git, постарайтесь освободиться от всего, что вы знали о других СКВ, таких как Subversion или Perforce. В Git’е совсем не такие понятия об информации и работе с ней как в других системах, хотя пользовательский интерфейс очень похож. Знание этих различий защитит вас от путаницы при использовании Git’а.
Главное отличие Git’а от любых других СКВ (например, Subversion и ей подобных) — это то, как Git смотрит на свои данные. В принципе, большинство других систем хранит информацию как список изменений (патчей) для файлов. Эти системы (CVS, Subversion, Perforce, Bazaar и другие) относятся к хранимым данным как к набору файлов и изменений, сделанных для каждого из этих файлов во времени.
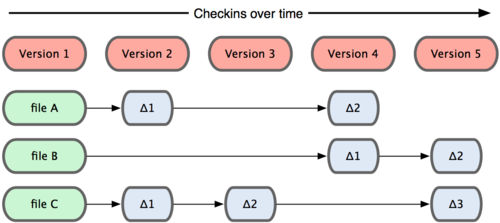
Рисунок 1-4. Другие системы хранят данные как изменения к базовой версии для каждого файла.
Git не хранит свои данные в таком виде. Вместо этого Git считает хранимые данные набором слепков небольшой файловой системы. Каждый раз, когда вы фиксируете текущую версию проекта, Git, по сути, сохраняет слепок того, как выглядят все файлы проекта на текущий момент. Ради эффективности, если файл не менялся, Git не сохраняет файл снова, а делает ссылку на ранее сохранённый файл. То, как Git подходит к хранению данных.
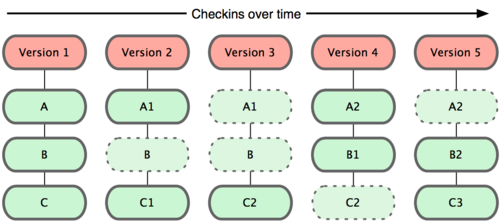
Рисунок 1-5. Git хранит данные как слепки состояний проекта во времени.
Это важное отличие Git’а от практически всех других систем контроля версий. Из-за него Git вынужден пересмотреть практически все аспекты контроля версий, которые другие системы переняли от своих предшественниц. Git больше похож на небольшую файловую систему с невероятно мощными инструментами, работающими поверх неё, чем на просто СКВ. Позже, коснувшись работы с ветвями в Git’е, мы узнаем, какие преимущества даёт такое понимание данных.
Для совершения большинства операций в Git’е необходимы только локальные файлы и ресурсы, т.е. обычно информация с других компьютеров в сети не нужна. Если вы пользовались централизованными системами, где практически на каждую операцию накладывается сетевая задержка, вы, возможно, подумаете, что боги наделили Git неземной силой. Поскольку вся история проекта хранится локально у вас на диске, большинство операций кажутся практически мгновенными.
К примеру, чтобы показать историю проекта, Git’у не нужно скачивать её с сервера, он просто читает её прямо из вашего локального репозитория. Поэтому историю вы увидите практически мгновенно. Если вам нужно просмотреть изменения между текущей версией файла и версией, сделанной месяц назад, Git может взять файл месячной давности и вычислить разницу на месте, вместо того чтобы запрашивать разницу у СКВ-сервера или качать с него старую версию файла и делать локальное сравнение.
Кроме того, работа локально означает, что мало чего нельзя сделать без доступа к Сети или VPN. Если вы в самолёте или в поезде и хотите немного поработать, можно спокойно делать коммиты, а затем отправить их, как только станет доступна сеть. Если вы пришли домой, а VPN-клиент не работает, всё равно можно продолжать работать. Во многих других системах это не возможно или же крайне неудобно. Например, используя Perforce, вы мало что можете сделать без соединения с сервером. Работая с Subversion и CVS, вы можете редактировать файлы, но сохранить изменения в вашу базу данных нельзя (потому что она отключена от репозитория). Вроде ничего серьёзного, но потом вы удивитесь, насколько это меняет дело.
Перед сохранением любого файла Git вычисляет контрольную сумму, и она становится индексом этого файла. Поэтому невозможно изменить содержимое файла или каталога так, чтобы Git не узнал об этом. Эта функциональность встроена в сам фундамент Git’а и является важной составляющей его философии. Если информация потеряется при передаче или повредится на диске, Git всегда это выявит.
Механизм, используемый Git’ом для вычисления контрольных сумм, называется SHA-1 хешем. Это строка из 40 шестнадцатеричных символов (0-9 и a-f), вычисляемая в Git’е на основе содержимого файла или структуры каталога. SHA-1 хеш выглядит примерно так:
24b9da6552252987aa493b52f8696cd6d3b00373
Работая с Git’ом, вы будете встречать эти хеши повсюду, поскольку он их очень широко использует. Фактически, в своей базе данных Git сохраняет всё не по именам файлов, а по хешам их содержимого.
Практически все действия, которые вы совершаете в Git’е, только добавляют данные в базу. Очень сложно заставить систему удалить данные или сделать что-то неотменяемое. Можно, как и в любой другой СКВ, потерять данные, которые вы ещё не сохранили, но как только они зафиксированы, их очень сложно потерять, особенно если вы регулярно отправляете изменения в другой репозиторий.
Поэтому пользоваться Git’ом — удовольствие, потому что можно экспериментировать, не боясь что-то серьёзно поломать. Подробнее о том, как Git хранит свои данные и как восстановить то, что кажется уже потерянным, мы рассмотрим позже в курсе лекций.
Теперь внимание. Это самое важное, что нужно помнить про Git, если вы хотите, чтобы дальше изучение шло гладко. В Git’е файлы могут находиться в одном из трёх состояний: зафиксированном, изменённом и подготовленном. “Зафиксированный” значит, что файл уже сохранён в вашей локальной базе. К изменённым относятся файлы, которые поменялись, но ещё не были зафиксированы. Подготовленные файлы — это изменённые файлы, отмеченные для включения в следующий коммит.
Таким образом, в проектах, использующих Git, есть три части:
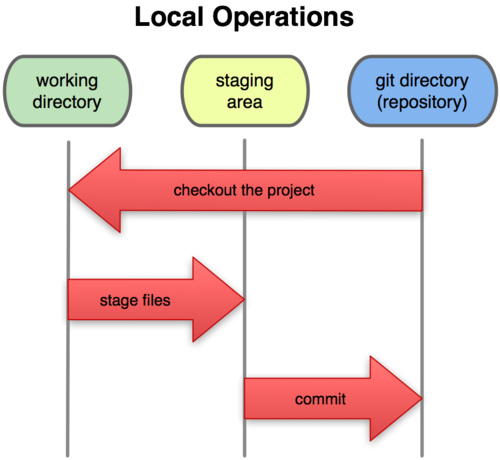
Рисунок 1-6. Рабочий каталог, область подготовленных файлов, каталог Git’а.
Каталог Git’а — это место, где Git хранит метаданные и базу данных объектов вашего проекта. Это наиболее важная часть Git’а, и именно она копируется, когда вы клонируете репозиторий с другого компьютера.
Рабочий каталог — это извлечённая из базы копия определённой версии проекта. Эти файлы достаются из сжатой базы данных в каталоге Git’а и помещаются на диск для того, чтобы вы их просматривали и редактировали.
Область подготовленных файлов — это обычный файл, обычно хранящийся в каталоге Git’а, который содержит информацию о том, что должно войти в следующий коммит. Иногда его называют индексом (index), но в последнее время становится стандартом называть его областью подготовленных файлов (staging area).
Стандартный рабочий процесс с использованием Git’а выглядит примерно так:
Если рабочая версия файла совпадает с версией в каталоге Git’а, файл считается зафиксированным. Если файл изменён, но добавлен в область подготовленных данных, он подготовлен. Если же файл изменился после выгрузки из БД, но не был подготовлен, то он считается изменённым. Поподробнее об этих трёх состояниях и как можно либо воспользоваться этим, либо пропустить стадию подготовки мы рассмотрим на следующей лекции.
Настало время немного ознакомиться с использованием Git’а. Первое, что вам необходимо сделать, — установить его. Есть несколько способов сделать это; два основных — установка из исходников и установка собранного пакета для вашей платформы.
Если есть возможность, то, как правило, лучше установить Git из исходных кодов, поскольку так вы получите самую свежую версию. Каждая новая версия Git’а обычно включает полезные улучшения пользовательского интерфейса, поэтому получение последней версии — часто лучший путь, если, конечно, вас не затрудняет установка программ из исходников. К тому же, многие дистрибутивы Linux содержат очень старые пакеты. Поэтому, если только вы не на очень свежем дистрибутиве или используете пакеты из экспериментальной ветки, установка из исходников может быть самым выигрышным решением.
Для установки Git’а вам понадобятся библиотеки, от которых он зависит:
Например, если в вашей системе менеджер пакетов — yum (Fedora), или apt-get (Debian, Ubuntu), можно воспользоваться следующими командами, чтобы разрешить все зависимости:
$ yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
$ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev
Установив все необходимые библиотеки, можно идти дальше и скачать последнюю версию с сайта Git’а:
http://git-scm.com/download
Теперь скомпилируйте и установите:
$ tar -zxf git-1.7.2.2.tar.gz
$ cd git-1.7.2.2
$ make prefix=/usr/local all
$ sudo make prefix=/usr/local install
После этого вы можете скачать Git с помощью самого Git’а, чтобы получить обновления:
$ git clone git://git.kernel.org/pub/scm/git/git.git
Если вы хотите установить Git под Linux как бинарный пакет, это можно сделать, используя обычный менеджер пакетов вашего дистрибутива. Если у вас Fedora, можно воспользоваться yum’ом:
$ yum install git-core
Если же у вас дистрибутив, основанный на Debian, например, Ubuntu, попробуйте apt-get:
$ apt-get install git
Есть два простых способа установить Git на Mac. Самый простой — использовать графический инсталлятор Git’а, который вы можете скачать со страницы на Google Code:
http://code.google.com/p/git-osx-installer
Рисунок 1-7. Инсталлятор Git’а под OS X.
Другой распространённый способ установки Git’а — через MacPorts (http://www.macports.org). Если у вас установлен MacPorts, установите Git так:
$ sudo port install git-core +svn +doc +bash_completion +gitweb
Вам не обязательно устанавливать все дополнения, но, вероятно, вам понадобится +svn, если вы когда-нибудь захотите использовать Git вместе с репозиториями Subversion.
Установить Git в Windows очень просто. У проекта msysGit процедура установки — одна из самых простых. Просто скачайте exe-файл инсталлятора со страницы проекта на GitHub’е и запустите его:
http://msysgit.github.com/
После установки у вас будет как консольная версия (включающая SSH-клиент, который пригодится позднее), так и стандартная графическая.
Пожалуйста, используйте Git только из командой оболочки, входящей в состав msysGit, потому что так вы сможете запускать сложные команды, приведённые в примерах в настоящей книге. Командная оболочка Windows использует иной синтаксис, из-за чего примеры в ней могут работать некорректно.
Теперь, когда Git установлен в вашей системе, хотелось бы сделать кое-какие вещи, чтобы настроить среду для работы с Git’ом под себя. Это нужно сделать только один раз — при обновлении версии Git’а настройки сохранятся. Но вы можете поменять их в любой момент, выполнив те же команды снова.
В состав Git’а входит утилита git config, которая позволяет просматривать и устанавливать параметры, контролирующие все аспекты работы Git’а и его внешний вид. Эти параметры могут быть сохранены в трёх местах:
/etc/gitconfig содержит значения, общие для всех пользователей системы и для всех их репозиториев. Если при запуске git config указать параметр --system, то параметры будут читаться и сохраняться именно в этот файл.~/.gitconfig хранит настройки конкретного пользователя. Этот файл используется при указании параметра --global..git/config) в том репозитории, где вы находитесь в данный момент. Эти параметры действуют только для данного конкретного репозитория. Настройки на каждом следующем уровне подменяют настройки из предыдущих уровней, то есть значения в .git/config перекрывают соответствующие значения в /etc/gitconfig.В системах семейства Windows Git ищет файл .gitconfig в каталоге $HOME (C:\Documents and Settings\$USER или C:\Users\$USER для большинства пользователей). Кроме того Git ищет файл /etc/gitconfig, но уже относительно корневого каталога MSys, который находится там, куда вы решили установить Git, когда запускали инсталлятор.
Первое, что вам следует сделать после установки Git’а, — указать ваше имя и адрес электронной почты. Это важно, потому что каждый коммит в Git’е содержит эту информацию, и она включена в коммиты, передаваемые вами, и не может быть далее изменена:
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.com
Повторюсь, что, если указана опция --global, то эти настройки достаточно сделать только один раз, поскольку в этом случае Git будет использовать эти данные для всего, что вы делаете в этой системе. Если для каких-то отдельных проектов вы хотите указать другое имя или электронную почту, можно выполнить эту же команду без параметра --global в каталоге с нужным проектом.
Вы указали своё имя, и теперь можно выбрать текстовый редактор, который будет использоваться, если будет нужно набрать сообщение в Git’е. По умолчанию Git использует стандартный редактор вашей системы, обычно это Vi или Vim. Если вы хотите использовать другой текстовый редактор, например, Emacs, можно сделать следующее:
$ git config --global core.editor emacs
Другая полезная настройка, которая может понадобиться — встроенная diff-утилита, которая будет использоваться для разрешения конфликтов слияния. Например, если вы хотите использовать vimdiff:
$ git config --global merge.tool vimdiff
Git умеет делать слияния при помощи kdiff3, tkdiff, meld, xxdiff, emerge, vimdiff, gvimdiff, ecmerge и opendiff, но вы можете настроить и другую утилиту.
Если вы хотите проверить используемые настройки, можете использовать команду git config --list, чтобы показать все, которые Git найдёт:
$ git config --list
user.name=Scott Chacon
user.email=schacon@gmail.com
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=auto
...
Некоторые ключи (названия) настроек могут появиться несколько раз, потому что Git читает один и тот же ключ из разных файлов (например из /etc/gitconfig и ~/.gitconfig). В этом случае Git использует последнее значение для каждого ключа.
Также вы можете проверить значение конкретного ключа, выполнив git config {ключ}:
$ git config user.name
Scott Chacon
Если вам нужна помощь при использовании Git’а, есть три способа открыть страницу руководства по любой команде Git’а:
$ git help <команда>
$ git <команда> --help
$ man git-<команда>
Например, так можно открыть руководство по команде config:
$ git help config
Эти команды хороши тем, что ими можно пользоваться всегда, даже без подключения к сети. Если руководства и этой книги недостаточно и вам нужна персональная помощь, вы можете попытаться поискать её на каналах #git и #github IRC-сервера Freenode (irc.freenode.net). Обычно там сотни людей, отлично знающих Git, которые могут помочь.
Теперь у вас должно быть общее понимание, что такое Git, и в чём его отличие от тех ЦСКВ, которыми вы, вероятно, пользовались раньше. Также у вас должна быть установлена рабочая версия Git’а с вашими личными настройками. Настало время перейти к изучению основ Git’а.